
A la découverte d'Azure Search
Créer un moteur de recherche au sein de son application est toujours complexe. Sur quels critères l'utilisateur va effectuer sa recherche ? Comment donner un poids à certains critères plus important que d'autres ? Comment gérer une recherche sur des données venant de plusieurs providers différents ? etc.
Pour résoudre ces problématiques, Azure propose la brique Azure Search. Il s'agit d'une solution de recherche, exposée sous la forme de service (PaaS), qui permet d'indexer des données, puis de les requêter via une API REST (également packagée dans une dll .NET). Azure se charge de mettre en place l'infrastructure nécessaire et propose, comme pour tous les services PaaS, une forte élasticité ainsi qu'une haute disponibilité.
Voyons ensemble comment utiliser ce service.
Création du service Azure
La création du service se fait évidemment depuis le portail Azure : https://portal.azure.com. Une recherche sur 'azure search' vous permettra d'accéder à la fenêtre de création : 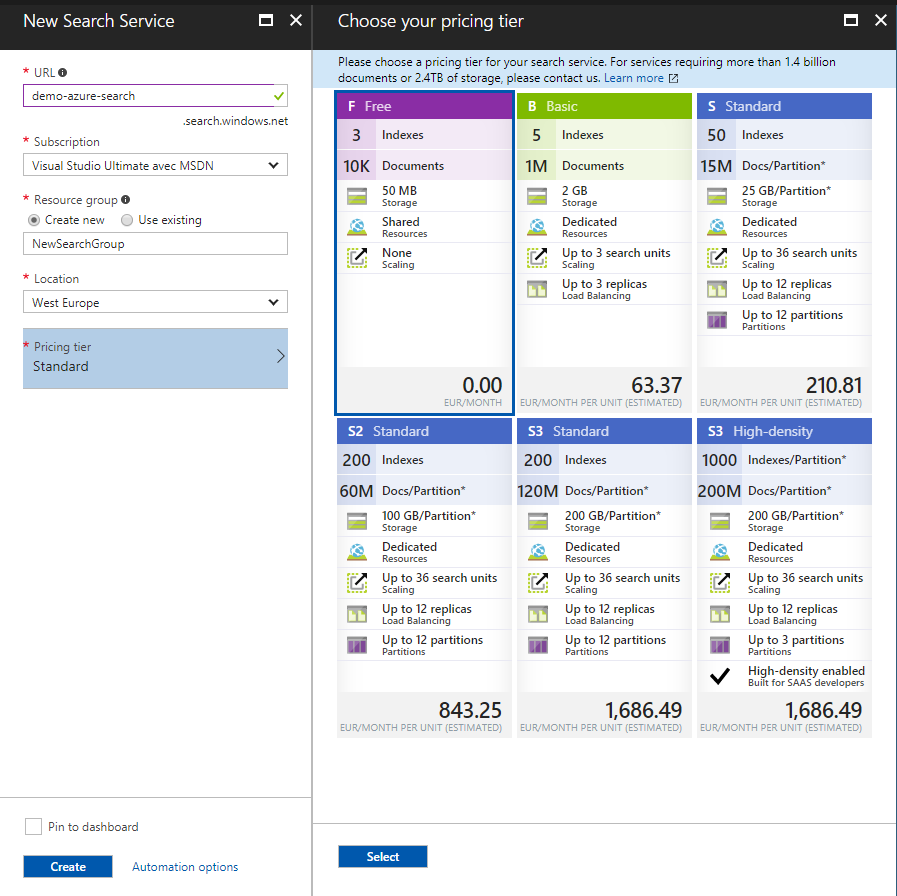
Vous devrez renseigner un nom unique et, de manière classique, la souscription à utiliser, le groupe de ressource, la localisation ainsi qu'un pricing. Attention sur ce dernier point, par défaut vous serez positionné sur du Standard qui coûte quand même plus de 200€ par mois, donc pensez à bien passer sur du Free pour vos tests.
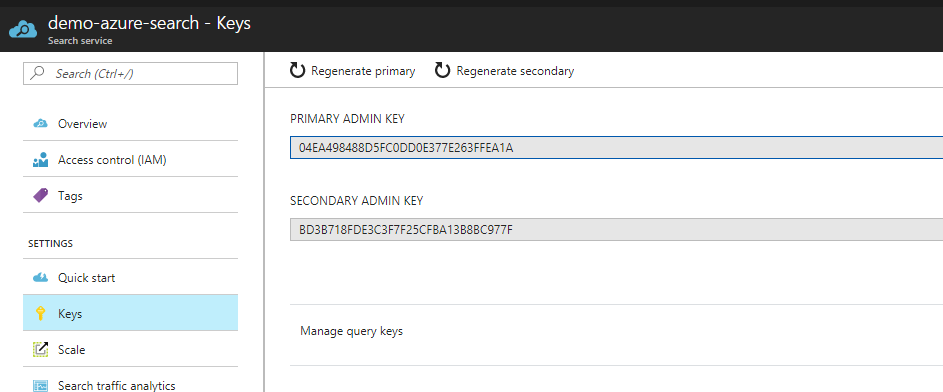
Vous trouverez alors les clefs d'accès (nécessaires pour communiquer avec votre Azure Search) dans la partie Keys.
Création et peuplement d'un index
La manipulation et l'interaction avec Azure Search se fait soit en passant par une API REST, soit en passant par le package nuget Microsoft.Azure.Search. Pour la suite de l'article, on utilisera le package Nuget mais le séquencement se déroule de manière identique en passant par l'API REST. Ce package expose la classe Microsoft.Azure.Search.SearchServiceClient permettant d'interagir avec le service Azure. Son instanciation se fait simplement en fournissant le nom du service ainsi qu'une clef d'accès.
var searchService = new SearchService(searchServiceName, searchServiceKey);
La première étape consiste à créer un index, correspondant à une collection de documents (on pourrait comparer un index à une table dans du stockage en base de données). Pour cela, il faut passer par la classe Microsoft.Azure.Search.SearchServiceClient qui expose une propriété Indexes, représentant les index du service, sur laquelle on pourra accéder à des méthodes de création / suppression / mise à jour.
Un index est constitué d'un ensemble de champs et est identifié par un nom.
var fields = new Field[]
{
new Field("id", DataType.String) { IsKey = true },
new Field("code", DataType.String) { IsSearchable = true, IsFilterable = true },
new Field("username", DataType.String) { IsRetrievable = false },
new Field("author", DataType.String) { IsSearchable = true, IsFilterable = true },
new Field("isPublished", DataType.Boolean) { IsFilterable = true },
new Field("publishDate", DataType.DateTimeOffset) { IsFilterable = true },
new Field("tags", DataType.Collection(DataType.String)) { IsSearchable = true, IsFilterable = true, IsFacetable = true },
new Field("mainCategory", DataType.String) { IsSearchable = true, IsFilterable = true, IsFacetable = true },
new Field("secondaryCategories", DataType.Collection(DataType.String)) { IsSearchable = true, IsFilterable = true, IsFacetable = true },
new Field("title", DataType.String) { IsSearchable = true, IsSortable = true },
new Field("summary", DataType.String) { IsSearchable = true },
new Field("content", DataType.String) { IsSearchable = true }
};
var index = new Microsoft.Azure.Search.Models.Index
{
Name = "posts",
Fields = fields
};
Chaque champ possède un type et un ensemble de propriétés indiquant ce qu'il est possible de faire sur ce champ :
- IsFacetable : indique si le champ peut être utilisé en tant que facette (plus d'infos ici sur la recherche par facette)
- IsFilterable : indique si le champ peut être utilisé pour filtrer
- IsKey : indique si le champ est la clef de l'entrée dans l'index (il ne peut y avoir qu'un seul champ positionné sur IsKey et il doit être de type String)
- IsRetrievable : indique si le champ doit être retourné par l'index (positionné à true par défaut)
- IsSearchable : indique si le champ peut être utilisé pour une recherche
- IsSortable : indique si le champ peut être utilisé pour trier
Une fois l'index instancié, la méthode CreateAsync permet de le créer sur l'Azure Search.
if (!await _serviceClient.Indexes.ExistsAsync(index.Name))
{
await _serviceClient.Indexes.CreateAsync(index);
}
Il reste maintenant à peupler l'index avec des données. Pour cela, il faut créer une instance de la classe Microsoft.Azure.Search.Models.IndexBatch représentant une action d'upload, de merge ou de suppression de documents d'un index. La méthode IndexAsync, exposée par la propriété Documents de la classe Index, permet ensuite d'envoyer le batch à l'index.
var batch = IndexBatch.Upload(posts); await index.Documents.IndexAsync(batch);
Les documents envoyés à l'index doivent respecter les champs définis par l'index. Dans notre cas, le modèle est le suivant :
[SerializePropertyNamesAsCamelCase]
public class PostSearchModel
{
public string Id { get; set; }
public string Code { get; set; }
public string Title { get; set; }
public string Summary { get; set; }
public string Content { get; set; }
public string Username { get; set; }
public string Author { get; set; }
public bool IsPublished { get; set; }
public DateTime PublishDate { get; set; }
public string MainCategory { get; set; }
public ICollection<string> Tags { get; set; }
public ICollection<string> SecondaryCategories { get; set; }
}
A noter que l'attribut Microsoft.Azure.Search.Models.SerializePropertyNamesAsCamelCase permet de s'assurer que les noms des propriétés Pascal-case soient correctement mappés aux noms Camel-case des champs de l'index.
Déclenchement d'une recherche
Maintenant que l'index est peuplé, nous allons pouvoir déclencher des recherches. Pour cela, il faut commencer par déclarer nos paramètres de recherche dans une instance de la classe Microsoft.Azure.Search.Models.SearchParameters.
var searchParams = new SearchParameters
{
Skip = skip,
Top = take,
Filter = $"isPublished eq true and publishDate le {DateTime.UtcNow:O}"
};
La code précédent permet d'indiquer que l'on souhaite filtrer sur les documents de l'index dont la propriété IsPublished est à true et la propriété PublishDate est inférieur à maintenant. Les propriétés Skip et Top permettent de récupérer les documents de manière paginée. Il est existe beaucoup d'autres paramètres permettant d'affiner sa recherche, je vous laisse consulter la documentation de la classe SearchParameters pour plus d'informations.
L'exécution de la requête se fait via une instance de la classe Microsoft.Azure.Search.SearchIndexClient qu'il est possible de récupérer depuis la propriété Indexes de la classe Microsoft.Azure.Search.SearchServiceClient.
var searchIndexClient = searchService.Indexes.GetClient(index.Name);
La classe Microsoft.Azure.Search.SearchIndexClient possède une propriété Documents qui expose une méthode SearchAsync<T> déclenchant la recherche.
var result = await indexClient.Documents.SearchAsync<PostSearchModel>(searchText, searchParams);
Le résultat de cette recherche possède notamment les propriétés Count représentant le nombre total de résultats de la recherche et Results contenant les résultats de la recherche. La propriété Results est de type SearchResult<T>, donc dans notre cas SearchResult<PostSearchModel>, qui contient le document retourné de type T ainsi qu'un score. Ce score représente la pertinence du résultat par rapport aux autres documents de la recherche (plus le score est haut, plus le document correspond à la recherche).
Monitoring
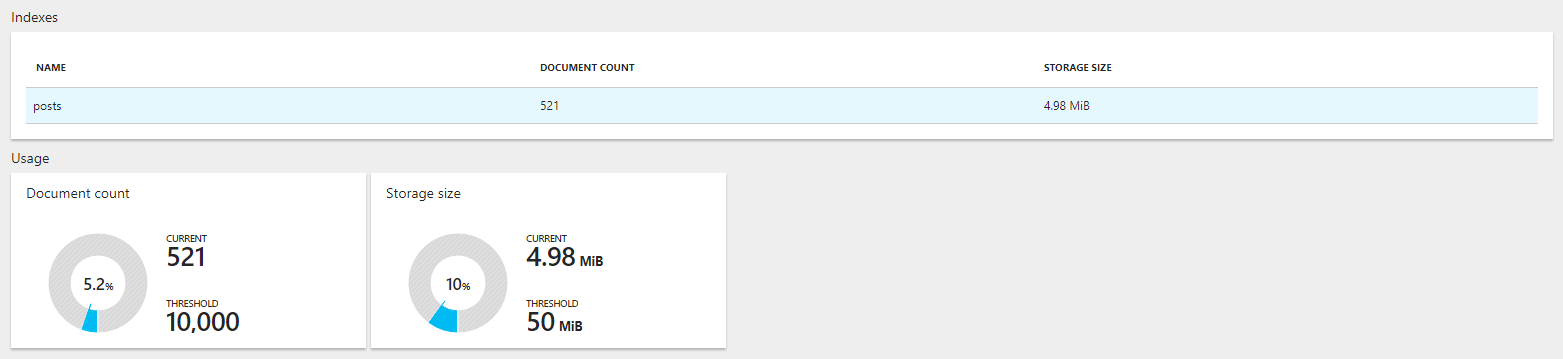
Sur son portail, Azure propose quelques métriques permettant de visualiser l'état de son service Azure Search. On peut notamment y voir l'état des index ainsi que l'usage global du service Azure Search (utile notamment pour upscaller ou downscaller).
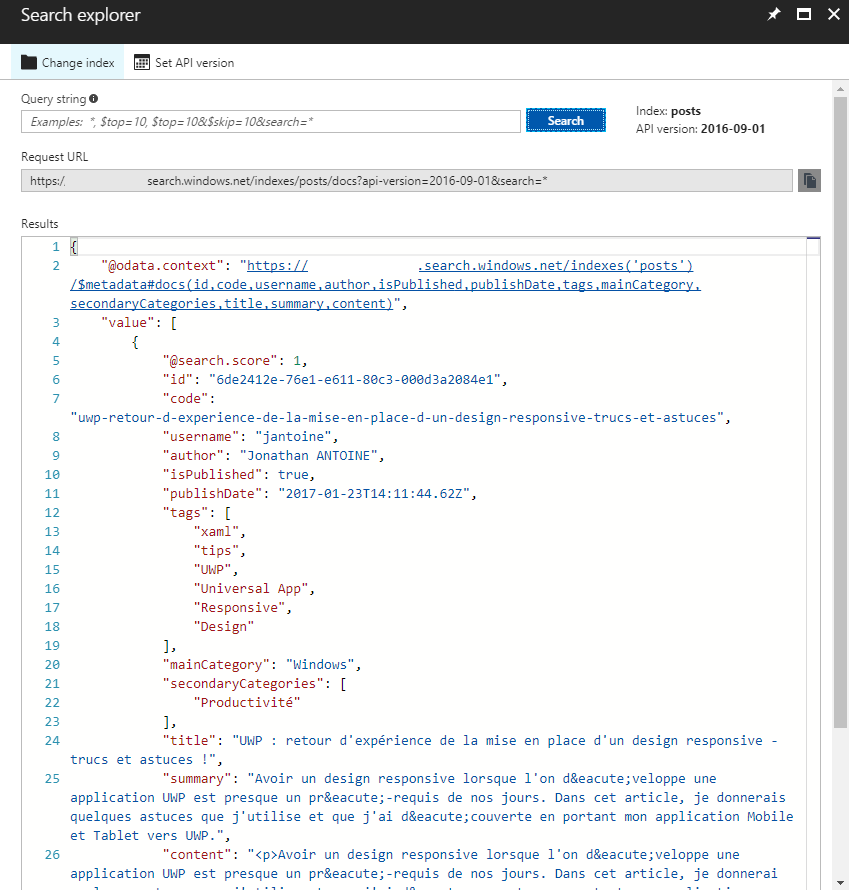
Le portail propose également une vue Search explorer permettant de requêter un index.
En conclusion
La mise en place d'Azure Search est extrêment simple comme on a pu le voir et nous permet de nous abstraire de toute la complexité inhérente aux moteurs de recherche. Evidemment, nous n'avons pas les mêmes possibilités qu'avec un moteur plus complet comme Apache Lucene, mais c'est largement suffisant pour proposer une recherche de qualité à moindre coût.
Bonnes recherches !


Commentaires