
SQLite, UWP et Windows Store : optimisation des performances - ma démarche
Ces derniers temps, j'interviens beaucoup en clientèle pour accompagner des équipes de développement à améliorer les performances de leurs applications Windows (UWP, Windows 8.1, etc.). Cela se traduit souvent par une amélioration des temps de chargement des données stockées dans une base SQLite. Dans ce billet, je présenterais mon plan d'investigation typique et j'en profite ainsi pour commencer l'écriture d'une série d'articles (coucou Aurélie !) sur ce sujet qu'est Sqlite.
Les articles de la série :
- SQLite et performances : ne récupérez de la base que ce dont vous avez besoin #UWP
- Comment gérer les montées de version du stockage SQLite des applications #Windows
- Cet article.
- Bientôt : Améliorez les performances d'accès SQLite d'une application UWP Windows 10 IOT CORE sur un Raspberry PI
Est-ce un problème au niveau SQLite ?
La première chose à vérifier et qu'il s'agit bien d'un problème de chargement des données. En général cela se traduit par un affichage rapide de la page puis l'affichage d'un loader présent très/trop longtemps. Une fois ceci établi il suffit de confirmer rapidement avec quelques points d'arrêts dans le code pour s'assurer que c'est le chargement des données qui prends du temps.
L'important à retenir est qu'il ne faut pas foncer tête baissée en imaginant que le problème vient toujours d'SQLite !
Plan d'actions typique
Voici les différentes étapes que j'effectue systématiquement :
- Vérifier la version du driver SQLite,
- Vérifier les extensions utilisées,
- Aider le planificateur de requête,
- Tracer les reqûetes effectuées sur la base,
- Analyser les requêtes coûteuses,
- Optimisation des requêtes "couteuses et longues",
- Optimisation des algoritmes applicatifs,
- Repos.
La version du Driver SQLite
On pourrait imaginer qu'SQLite, présent depuis longtemps dans l'impitoyable univers informatique n'a que très peu de raisons d'évoluer et que les sorties de versions sont rares : c'est faux ! Il y a eu pas moins de 14 nouvelles versions en 2017 !
L'amélioration des performances est une préoccupation des développeurs du driver car celles-ci s'améliorent de versions en versions. Voici ci-dessous le graphique qu'ils proposent dans leur documentation (que je vous invite à lire ici). Il va sans dire que s'assurer d'utiliser les versions les plus récentes possibles doit donc être aussi votre préoccupation !
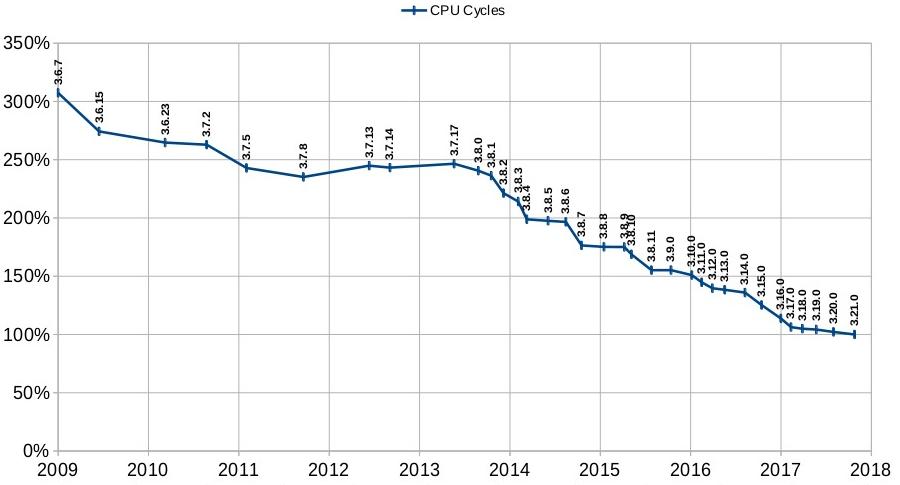
Pour ajouter SQLite à votre application, vous pouvez installer l'extension Visual Studio au niveau machine, la référencer au niveau de votre projet. Il est aussi possible d'utiliser le driver présent directement dans Windows mais vous ne serez pas forcément dans la version la plus à jour...
Vérifier les extensions utilisées
Il existe une pléthore de façon d'accéder à une base de données SQLite : je préfère de loin utiliser SQLite-net (explications de Teddy ici) mais il est aussi possible d'utiliser EF Core, le faire à la main, etc.
Souvent il existe aussi des systèmes de plugins permettant d'ajouter des fonctionnalités à la partie 'accès aux données' SQLite. Cela peut s'avérer très pratique et permet de gagner en productivité. Je vous recommande cependant de vous assurer du fonctionnement de ces extensions avant des les utiliser massivement.
Prenons par exemple la très connue "SQLite-Net extensions" qui permet de gérer facilement les relations one-to-one, one-to-many, etc. Vous pouvez en un appel récupérer un objet et les différentes entités qui lui sont liées mais saviez-vous que cela va potentiellement créer une requête supplémentaire par objet "en relation" et cela de manière récursive ? Si l'on ne fait pas attention, cela peut rapidement déclencher un trop grand nombre de requêtes.
Aider le planificateur de requêtes
La construction des requêtes par SQLite est réalisée par le query planner qui a besoin de statistiques pour savoir quel est le meilleur chemin à suivre. Ces statistiques ne sont PAS construites automatiquement.
Il est donc de bon goût de demander cette analyse régulièrement et la bonne pratique voudrait que cela soit réalisé avant la fermeture des connexions SQLite. Techniquement il suffit donc d'exécuter la requête SQLite suivante :
ANALYZE
Oui, oui il n'y a qu'un seul mot, c'est normal :)
Tracer les requêtes effectuées sur la base
L'étape suivante consiste à tracer les requêtes envoyées à la base et les afficher dans la console avec leur temps d'exécution. Afin de me faciliter la vie, j'ai pour habitude d'ajouter un petit utilitaire que j'appelle affectueusement "PerfMonitor" et qui permet de
- Tracer un temps d'exécution entre deux points,
- Tracer un temps d'exécution depuis une dernière mesure,
- Tracer le nombre de mesure de temps "global",
- Être utilisable facilement via un using.
internal class PerfMonitor : IDisposable
{
private static long measureDone;
private readonly string _name;
private readonly Stopwatch _stopWatch;
private long _lastTrace;
public PerfMonitor(string name)
{
_name = name;
_stopWatch = new Stopwatch();
_stopWatch.Start();
}
public void TraceSinceLast(string traceName)
{
var currentTrace = _stopWatch.ElapsedMilliseconds;
MetroEventSource.Log.Critical("PERF;"
+ traceName + ";"
+ (currentTrace - _lastTrace));
_lastTrace = currentTrace;
}
public long GetCurrentElapsedMilliseconds()
{
return _stopWatch.ElapsedMilliseconds;
}
public void Dispose()
{
_stopWatch.Stop();
System.Threading.Interlocked.Increment(ref measureDone);
MetroEventSource.Log.Critical("PERF;"
+ measureDone + ";"
+ _name + ";"
+ _stopWatch.ElapsedMilliseconds);
}
}
Je ne vais pas rentrer dans le détail sur chaque ORM mais me concentrer sur SQLite-Net : en utilisant les fichiers de code-source Sqlite.cs et SqliteAsync présents sur le github, il est simple de modifier le code source. On ajoute le code nécessaire en modifiant les deux méthodes suivantes : ExecuteDeferredQuery et ExecuteScalar, toutes les appels à la base passant par là. Par exemple, le code modifié d'ExecuteDeferredQuery ressemblera à :
public T ExecuteScalar<T>()
{
T val = default(T);
using (var d = new PerfMonitor(this.ToString()))
{
/* Appel SQL */
}
return val;
}
Détecter les requêtes suspectes
Une fois les requêtes tracées, vous devriez voir apparaîre de nombreuses lignes dans la console. Pour cela, il faut utiliser l'application de manière classique. La plupart du temps, les problèmes de performances sont identifiés sur des scenarii d'usage déjà identifiés et c'est sur ceux-là qu'il faut s'attarder. Attention, l'écriture de ces logs ralentit encore plus l'application et il faudra bien les désactiver avant de partir 🎵du côté de chez Prod🎵.
PERF;42;select * from "T_OhLa" where ("acc_Id" = ?)
PERF;3;select * from "T_Jolie" where ("acc_UserId" = ?)
PERF;404;select * from "T_Table" where ("acc_IdTable" = ?)
Il va ensuite falloir analyser toutes ces lignes et détecter les potentiels problèmes liés à l'utilisation d'SQLite. Je rencontre principalement 2 typologies de problèmes :
- Une ou plusieurs requêtes prennent vraiment trop longtemps : une ou plusieurs secondes pour requêter quelques centaines d'objets sur une table de plusieurs milliers d'objets ce n'est pas normal en général. SQLite est une base de données et on doit avoir de bien meilleures performances. Ce sont ce que j'appelle des requêtes couteuses et longues.
- Une ou plusieurs requêtes sont jouées bien trop souvent. Il s'agit dans la plupart des cas d'un problème d'algorithme applicatif.
Optimisation des requêtes "coûteuses et longues".
Si vous détectez qu'une requête prend vraiment beaucoup de temps c'est qu'il est nécessaire de l'optimiser. Je l'écris à nouveau : SQLite est un moteur de base de données et il est censé savoir gérer plusieurs milliers d'enregistrements assez facilement !
La première étape consiste à demander à SQLite de vous aider à comprendre son interprétation de votre reqûete. Il existe pour cela une commande : "EXPLAIN QUERY PLAN votre requête ici". Vous pouvez l'exécuter dans votre navigateur de base de données SQLite( mon préféré étant DB Browser for SQlite) pour avoir ce type de résultats :
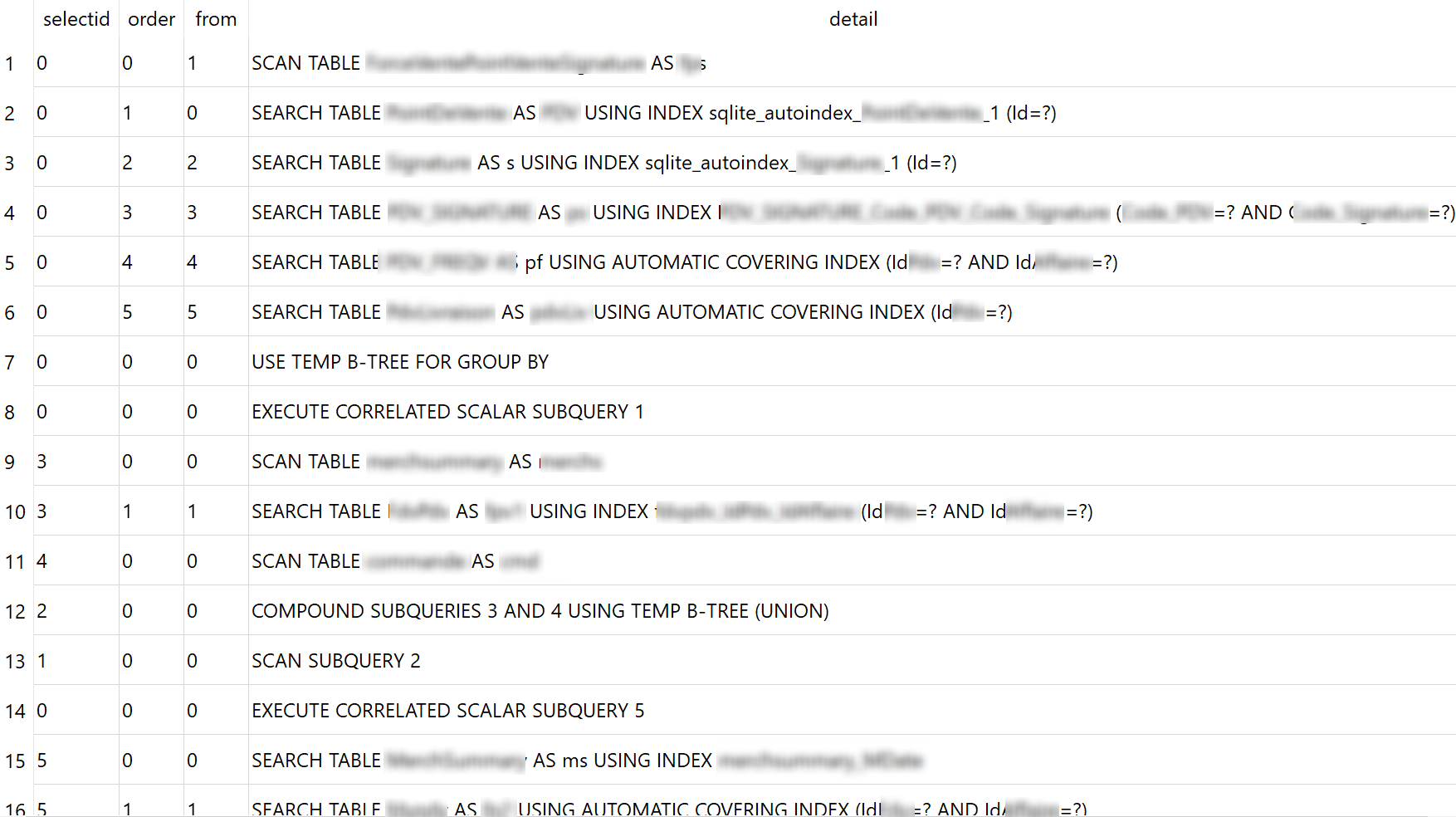
Vous avez devant vous les différentes étapes d'exécution de votre requête : indexes utilisés, exécution de sous-queries, etc. Ce qui vous intéresse notamment ici est ce qui est préfixé d'AUTOMATIC COVERING INDEX.

Un index covering est un index contenant toutes les colonnes utilisées par votre filtre ou jointure : dans ce cas SQLite n'a même pas besoin de faire une lecture dans la table et il est donc beaucoup plus rapide. Par contre s'il est automatique c'est parce qu'il est créé à la volée et détruit après la requête (ce comportement est désactivable d'ailleurs)... ce n'est donc pas forcément très performant. L'idée d'optimisation ici est donc de créer à l'avance un index correspondant au besoin de votre requête. Cela sera surement un peu (tout petit peu) moins performant lors de l'insert unitaire d'éléments mais le gain en termes de temps de lecture sera énorme.
La résolution de ces problèmes consiste donc simplement à créer des index contenant toutes les colonnes de vos filtres/jointures. Vous pouvez faire cela sous la forme d'une montée de version de l'application au lancement de l'application par exemple.
Optimisation des algorithmes applicatifs
Un comportement fréquemment rencontré est de charger les objets dont vous avez besoin unitairement au moment où vous en avez besoin. Cela fonctionne très bien au début et puis, petit à petit la volumétrie change et vous vous retrouvez sans vous en rendre compte (généralement, on ne logge pas les requêtes SQLite) avec des milliers de requêtes exécutées sur votre base. Ainsi si vous constatez que la même requête avec juste un changement de filtre est effectué plusieurs dizaines/centaines/milliers de fois : il y a un problème :)
La solution selon moi ici est au niveau de vos algorithmes. Je vais être obligé de rester théorique ici mais souvent il s'agit du parcours d'un "arbre" avec des demandes d'informations sur chacune des branches/feuilles. Souvent il est intéressant de faire une lecture de tous les objets en base en amont du parcours de l'arbre et d'utiliser les objets "en mémoire" dans les calculs réalisés dans l'arbre. Vous vous rendrez parfois compte que vous ne lirez plus que 3 éléments en base une fois au début du traitement plutôt qu'une fois par feuille (= des milliers de fois) pendant le parcours de l'arbre de traitement. Bien sûr, tout cela va rester spécifique à votre traitement et en cas de besoin, n'hésitez pas à solliciter l'aide de notre experte Aurélie.
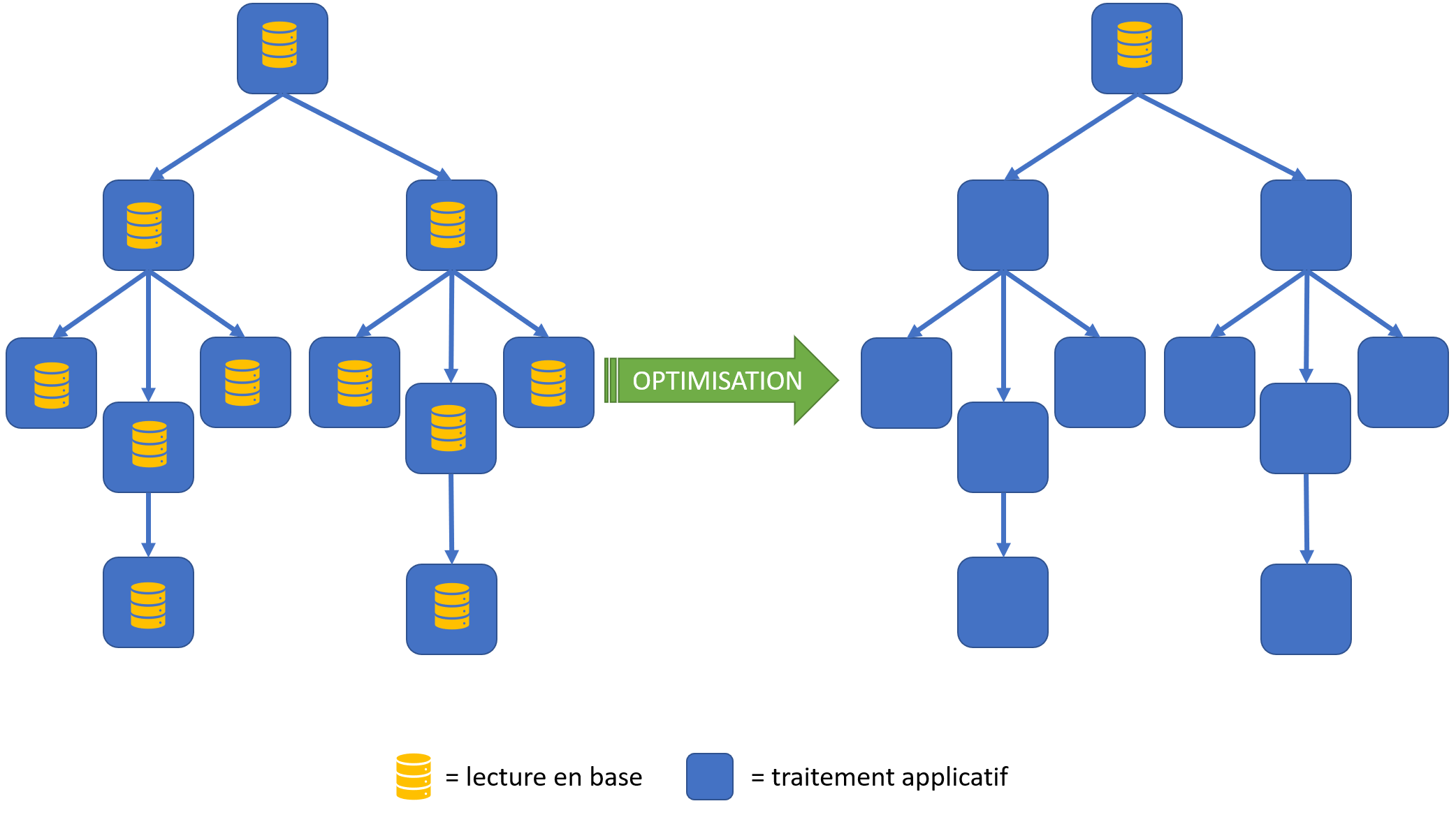
Utilisez-vous d'autres techniques ?


Commentaires