
Une méthode de projet pragmatique ?
Il n'y a pas un projet unique et la méthode miracle n'existe pas (encore) ! Dans cet article je vais vous présenter une façon de faire que je trouve plutôt efficace après l'avoir éprouvée pendant quelques temps et projets. Elle est très inspirée de la méthodologie agile SCRUM mais je préfère dès fois ne pas appliquer à la lettre une norme si elle devient un frein.
Je sais d'avance que tout le monde que cette méthode est discutable et certains seront peut être même offusqués au plus haut point par ce qu'ils liront mais c'est l'occasion pour nous d'échanger paisiblement dans les commentaires !
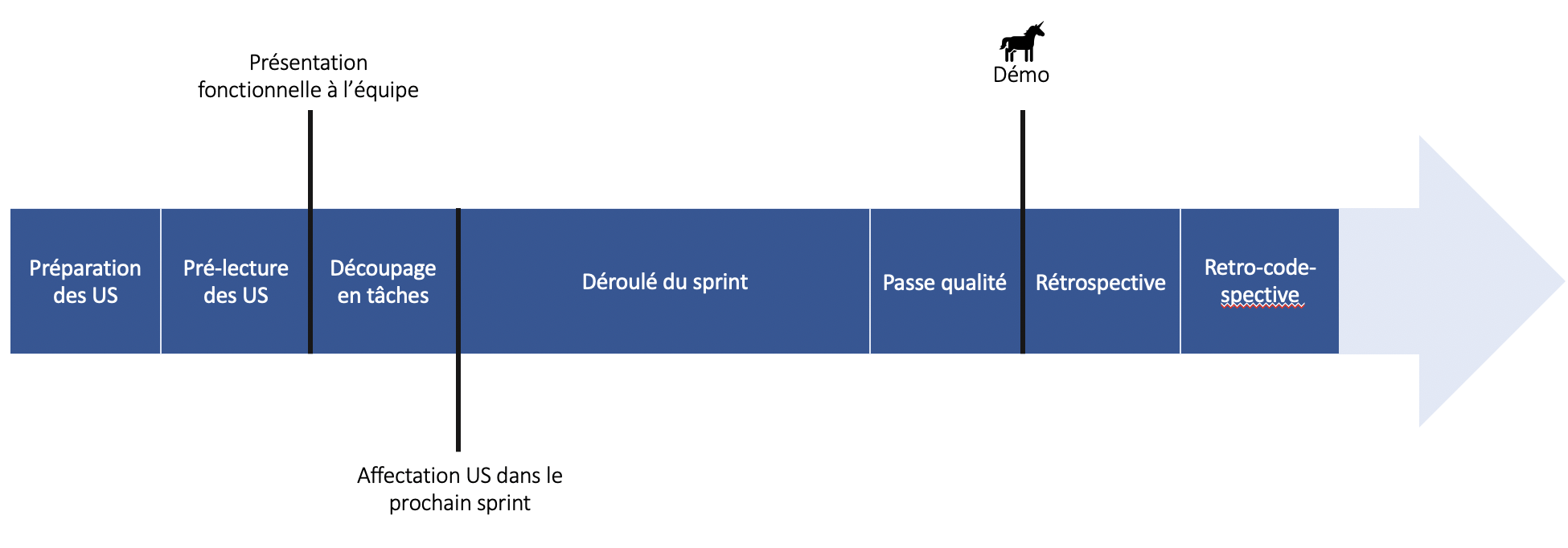
Voici la ligne de temps de ce que je souhaite vous présenter :
Différentes personnes impliquées
Plusieurs acteurs font partie intégrante d'un projet :
- Le Project Owner (PO) : il est le garant du produit développé, il est le seul à décider de la priorité d'une fonctionnalité par rapport à une autre.
- Les développeurs : ils développent les fonctionnalités attendues sur le produit.
- Les développeurs seniors : des développeurs capables d'avoir une vision d'ensemble et de poser des briques d'architecture.
- Les testeurs : pour chaque fonctionnalité, il faut des personnes à même de tester la bonne réalisation de celle-ci. Dans l'idéal, des cas de tests et des critères d'acceptance sur les US sont aussi rédigés sur les US.
Liste de fonctionnalités (US) dans un backlog
Le PO est à même de produire à un instant t une liste des fonctionnalités attendues sur le produit. Cette liste est traduite en User Stories (US) dans un backlog. Certaines fonctionnalités sont plus des besoins techniques nécessaires et je ne m'empêche pas de demander la création de Technical Stories : elles sont au même niveau que les autres User Stories.
Dans la méthode Agile, on nomme les US d'une manière très précise "En tant que {Personne du projet} je veux XXX afin de YYY". Dans les faits, j'ai toujours trouvé cela assez lourd, avec peu de valeurs ajoutée et je préfère trouver ce genre de nommage : [EMPLACEMENT][Personne du projet] Ce que je veux. Par exemple "[FRONT][Utilisateur] Je veux afficher la liste de mes séries groupées par status".
Ce backlog doit à tout moment être priorisé par le PO (et uniquement le PO) : les US les plus importantes sont en haut, les moins importantes sont en bas et tout lecteur du backlog sait quelle fonctionnalité est plus importante qu'une autre. Cette priorisation évolue avec le temps et il est tout à fait possible de changer la priorité d'une US par rapport à une autre dans le backlog général. Pour chaque modification de priorité, il est important de prévenir l'équipe de développement (au daily meeting par exemple) car parfois le travail de certaines tâches nécessite certains prérequis techniques à faire en premier.
Chaque US doit porter la spécification qui lui correspond. Dans les faits, il ne faut pas être perfectionniste et demander que toutes les US soient spécifiées de manière ultra-précise mais il est important que les US les plus prioritaires soient décrites complètement par le PO dont cela est la responsabilité.
Une des difficultés très souvent rencontrée est d'avoir de "trop grosses US". Une US de ce type est en réalité une "Feature" sur Azure Dev Ops / VSTS et il est important de découper celles-ci en plusieurs US : cela permettra d'avoir des spécifications plus précises sur chaque US et de découper les développements en petits blocs "plus facilement" livrables et testables.
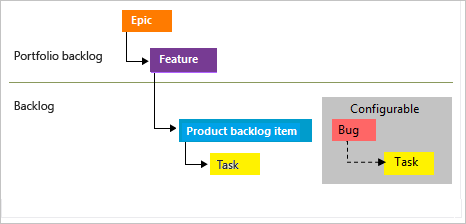
Dans cette organisation, j'aime considérer chaque bug au même niveau qu'une US : c'est au PO de décider si sa correction est prioritaire ou non par rapport à une autre fonctionnalité. Cela permet aussi de décider qu'une US est terminée même si il existe quelques défauts (les bugs) ce qui est plus compliqué si l'on ajoute les bugs comme enfant de l'US associée.
Spécifications d'une US
La spécification d'une US peut prendre plusieurs formes mais doit contenir selon moi ces informations dans son descriptif :
- L'attendu fonctionnel : qu'est ce que l'on attend du produit / de la plateforme.
- Les utilisateurs habilités pour effectuer l'action considérée.
- L'emplacement de cette fonctionnalité et son contexte d'utilisation.
- Une maquette (ou un wireframe à défaut). --> Il est donc bien sûr nécessaire d'anticiper ce besoin et de créer les maquettes avec notre designer préféré à l'avance.
- Un descriptif des champs : format, taille min, taille max, valeurs autorisées et refusées.
- Souvent oublié : la gestion des cas d'erreur. Est-ce que si un problème survient, cela bloque l'intégralité du processus ou on se contente de le logger techniquement ? Comment afficher le message d'erreur à l'utilisateur ?
- L'attendu technique si un certain niveau de performance est attendu par exemple.
Selon moi, il s'agit d'un exercice très difficile pour le PO car il faut réussir à traduire un besoin fonctionnel en spécifications compréhensibles et complètes pour les développeurs. Il est aussi impératif et difficile de garder une cohérence entre toutes les US correspondant à la fonctionnalité parente : chaque US s'inscrit dans un grand ensemble et il ne faut pas oublier une partie de la fonctionnalité ou du processus. Il est d'ailleurs important de s'abstenir d'avoir des préjugés sur ce que savent déjà les lecteurs des US et décrire même l'évident. Par exemple, tout le monde n'a pas la même définition du mot alpha numérique : accents ou non, caractères spéciaux ou non, espace ou non, etc. Cela est quelque fois fastidieux mais cette apparente perte de temps initiale peut vous faire gagner beaucoup de temps dans le futur car il est toujours plus long d'identifier une incohérence, son origine et d'attendre sa correction que de l'avoir développée une fois pour toute correctement. Centraliser ces définitions de termes dans un WIKI est une très bonne pratique !
Il est souvent tentant d'adjoindre une spécification sous la forme d'un fichier WORD de 30 pages. Selon moi il s'agit de quelque chose à éviter à tout prix. Il y a de grandes chances d'avoir une interprétation différente par chaque développeur la lisant ainsi que des "ha oui je n'avais pas lu cette petite ligne" (non je ne parle pas de votre contrat d'assurance mais bien d'une US). Le tout résultant en une implémentation ne correspondant pas à ce qui est attendu et donc de la frustration pour tout le monde.
Il faut donc bien prendre le temps de décrire complément l'US et ses attendus de la façon la plus concise et précise possible.
Pré-lecture et affinage des US
Une fois suffisamment d'US rédigées par le PO il est intéressant de faire relire celles-ci à l'intégralité de l'équipe de développement et tests. On bloque en général une après-midi dédiée à cet exercice juste à la fin du sprint précédent. L'objectif est que chaque personne puisse s'assurer de comprendre le descriptif complet fait de chaque US et anticiper les chantiers techniques qui en découleront.
Il faut se poser ces questions en relisant une US :
- Est-il possible de réaliser cela ?
- Est-ce que je comprends bien tous les termes employés : ne JAMAIS laisser une ambiguïté potentielle subsister.
- Est-ce que tous les cas possibles sont décrits dans l'US ?
- Est-ce cohérent avec les développements déjà mis en place ?
- Est-ce cohérent avec les autres US que j'ai pu déjà lire ?
- Y a t'il un risque technique potentiel à exprimer au PO : performance, qualité, disponibilité du service... ?
Il y a de grandes chances que cela soit l'opportunité de demander des précisions au PO qui sera peut être physiquement présent avec vous ou via un mail centralisant les différentes questions. Une fois les différentes questions ayant trouvé une réponse, il est nécessaire que le PO amende les US pour y intégrer les nouvelles informations. Une US sera ainsi le référentiel du travail à réaliser le plus à jour. VSTS a le bon goût d'historiser les modifications et vous aidera ainsi à revenir dans le passé si nécessaire.
Si les réponses ne peuvent être données et rédigées en live j'ai pour habitude de créer et placer un tag "Attente spécifications" sur les US incriminées. Une seconde relecture permettra de l'en enlever une fois tous les doutes levés. Il est aussi possible d'utiliser le status "Blocked" plus visible car avec une pastille rouge m'a fait remarqué Matthieu.
Présentation fonctionnelle à l'équipe
L'étape suivante consiste en une présentation fonctionnelle à l'équipe de développeurs et testeurs des attendus du prochain sprint et donc des US se trouvant en haut du backlog.
Cela permet de donner un objectif macroscopique aux prochaines semaines de développement. Souvent, les sprints se retrouvent affublés de surnoms et il n'est pas rare d'entendre : "on a fait cela sur le sprint Kamoulox" où Kamoulox est une fonctionnalité du produit développé.
Cet exercice est fait dans une séance relativement courte dépassant rarement la trentaine de minutes.
Découpage en tâches / estimations
La partie suivante consiste à découper les US du haut du backlog - les plus prioritaires - en tâches techniques.
Le découpage est réalisé dans la majorité des cas par l'ensemble des développeurs : cela permet à chacun de proposer une façon de faire technique, de comprendre celle qui sera choisie et de confronter sa transposition technique des spécifications fonctionnelles. Il arrive parfois que l'équipe soit trop conséquente pour que ces réunions soient efficaces et dans ce genre de contexte on peut choisir de n'impliquer que les développeurs ayant une appétence pour ce genre de travail. Ce genre de décision ne se fait pas sans contrepartie : il faut représenter les solutions techniques à chaque développeur non présent et s'astreindre d'avoir un descriptif très précis et complet dans les tâches créées.
Dans cette séance, le PO est obligatoirement présent pour pouvoir répondre à toute question levée sur les US en cours de découpage.
Chaque US est prise une par une dans l'ordre de priorité du backlog et pour chacune on découpe le travail technique a réaliser sous la forme de tâches VSTS. Dans chaque tâche on décrit l'attendu technique et on précise toutes les informations importantes : noms des composants techniques à créer, leur emplacement, la couverture complète par des tests, les éventuelles migrations de données impliquées, etc. Il est possible de jouer sur les tags pour indiquer s'il s'agit de travail relatif à du Front (Angular, Xamarin, etc.) ou du Backend (Asp.net core, Node.js, etc.). Il n'est pas rare non plus de préfixer les noms des tâches par [Back] ou [Front].
Une tâche terminée est une notion décidée en tant qu'équipe mais j'ai l'habitude de voir cela :
- Le travail de fond réalisé et correctement commenté.
- Les tests automatisés écrits.
- Les retours de Pull Request pris en compte.
- L'éventuelle documentation technique écrite.
- Suffisamment de commentaires dans le code.
Chaque tâche doit être estimée en heure. Traditionnellement, une tâche doit rester un travail relativement petit et ne pas dépasser plus de 2 jours de réalisation. La durée à placer est décidée de manière collégiale et au fur et à mesure des itérations de ce genre d'exercice, vous devriez voir apparaître des patterns récurrents : X heures pour une API, Y heures pour une nouvelle liste, etc. Normalement, si l'équipe de développement ne change pas, ce temps devrait aussi diminuer jusqu'à atteindre un point d'équilibre une fois les habitudes mises en place.
Découpage en sprint et affectation
Au commencent du projet, il est important de convenir d'une durée de sprint. Habituellement nous travaillons sur des itérations de 2 semaines.
Le sprint va constituer le lot de fonctionnalités que l'équipe de développement s'engage à réaliser.
À la fin la séance de découpage, il est facile de ne laisser dans le sprint que ce qui correspond à la capacité de production de l'équipe. Il est intéressant de laisser un peu de capacité libre afin de pouvoir intégrer des corrections de bugs urgents ou de préparer / configurer des environnements de démo (même si cela devrait être une US du sprint si cela est attendu).
Contrairement à ce qui se fait habituellement, je trouve cela intéressant d'affecter les différentes tâches du sprint aux développeurs plutôt que de laisser chacun piocher au fur et à mesure :
- Dans des équipes avec des compétences mixtes (front / back) cela permet de savoir si un développeur ne va pas se retrouver au chômage technique ou au contraire avoir plus de travail qu'il ne peut en faire.
- Cela permet à chacun de connaître à l'avance les tâches en particulier qu'il devra réaliser et de s'y intéresser encore plus précisément.
Bien sûr cela ne nous empêche pas de faire évoluer ces affectations pendant le déroulé du sprint si cela est nécessaire. Dans cette configuration, certains développeurs peuvent être dans l'attente du travail d'un autre développeur :il est donc important de bien répartir les affectations pour éviter cela.
Présentation technique à l'équipe
Si tous les membres de l'équipe de développement étaient présents lors de la séance de découpage, cette étape est inutile. Sinon, il est nécessaire de présenter les orientations techniques choisies pour la réalisation des différentes US.
Soit on fait cela en une seule "grande messe", soit on le fait personne par personne en fonction des US assignées. Dans tous les cas, il faut rédiger une documentation (WIKI, PPT, etc.) présentant les choix effectués.
Déroulé du sprint
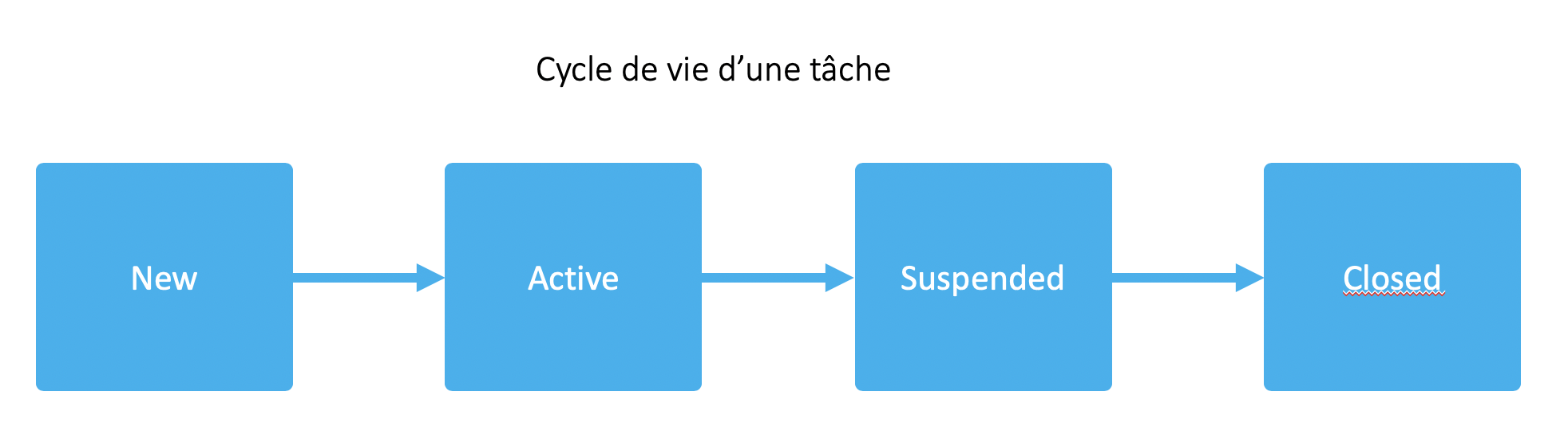
Au quotidien les développeurs vont prendre (passage au statut "active") les tâches qui leurs sont assignées du haut du sprint backlog vers le bas : du plus prioritaire au moins prioritaire. Une fois une tâche développée, une PR est créée (passage de la tâche au status "suspended" puis validée (passage de la tâche au status "closed" pour finalement être intégrée directement sur la branche principale.
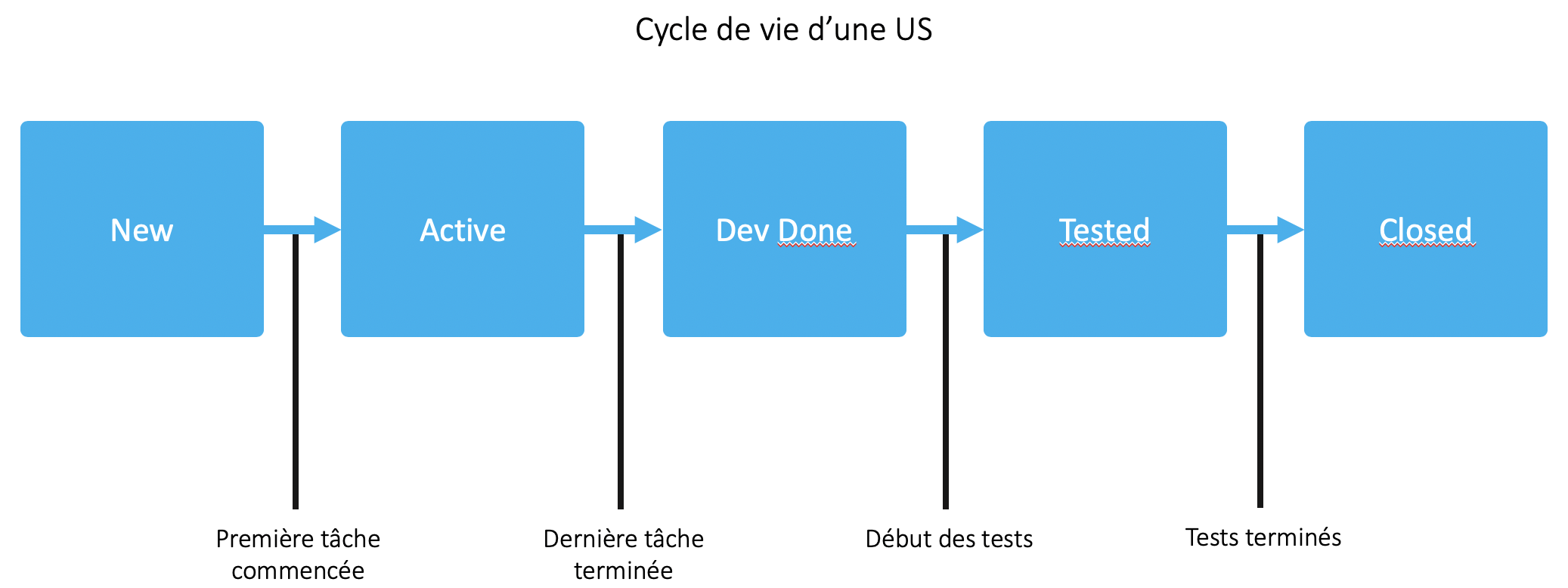
Un développeur prenant la première tâche d'une US prendra soin de passer cette dernière en active. Le développeur fermant la dernière tâche prendra le soin de passer l'US au statut "Dev Done", de l'assigner à un testeur qu'il préviendra. Le testeur pourra alors dérouler l'ensemble de ses tests, créer des bugs (ou pas !) et finalement fermer l'US. Je pars donc du principe que le testeur est en mesure de tester au fil de l'eau les fonctionnalités développées sans attendre la fin du sprint. Il est toujours plus simple de corriger les bugs à chaud que d'attendre le sprint suivant pour les corriger. Je reviendrai plus tard dans cet article sur la gestion des bugs.
Il arrive quelques fois que des oublis apparaissent et il est important qu'une personne vérifie chaque matin (ou plusieurs fois par jour) que tout est bien d'équerre au niveau du suivi des tâches. Ce rôle incombe en général au Project Lead de nos projets qui en profite pour faire une première passe de tests sur le produit lui même. J'ai quand même la douce illusion qu'un développeur teste aussi par lui même une fois sa PR mergée sur la branche cible... :)
Gestion des bugs
Un bug créé par un testeur est assigné au PO qui prendra soin de le placer dans le sprint backlog à la hauteur qu'il souhaite : est-ce plus ou moins prioritaire qu'une des fonctionnalités de ce sprint. Une fois la priorisation faite, le bug est assigné à un développeur senior qui découpera sa correction en tâches et affectera celles-ci aux autres développeurs.
J'avais indiqué qu'il fallait laisser un peu de marge pour corriger des bugs lors du remplissage du sprint avec des US. Une fois cette marge "comblée" il faudra décaler les corrections de bugs à un sprint ultérieur. Cependant, les bugs détectés sur des fonctionnalités du sprint courant restent à corriger sur ce même sprint en priorité car leur temps de corrections est normalement déjà pris en compte dans l'estimation d'implémentation de l'US.
Un défaut de cette pratique est qu'il est difficile de faire une planification précise de ce qui sera livré en fin de sprint car le backlog évolue constamment. S'il est nécessaire de savoir exactement le périmètre livré après un sprint alors il faut décaler les corrections de bugs des fonctionnalités "hors du sprint actuel" à un sprint ultérieur et les traiter de la même façon que les US.
Passe qualité
Il est utopique d'imaginer que pile à la date de fin du sprint, tout est terminé et parfait. Il est donc toujours intéressant de se garder une petite période de répit pour effectuer une passe qualité. Durant ce temps, on terminera les tâches non terminées car sous estimées, non prévues initialement car oubliées lors du découpage et corriger les bugs critiques remontés par l'équipe des testeurs. En général on planifie un ou deux jours pour ce travail.
Si certains développeurs se retrouvent sans travail à faire ils peuvent en profiter pour effectuer eux-même des tests manuels aléatoires sur le produit ou commencer à relire les US du haut du backlog en prévision du prochain sprint.
Démo !
Il est maintenant l'heure de faire la démonstration du développement réalisé au PO.Il s'agit d'une réunion (souvent dirigée par le Project Lead du projet) d'une demi-heure environ avec un récapitulatif des attendus, quelques statistiques sur le sprint passé et une demonstration en direct sur l'outil.
J'aime que cette dernière tâche incombe à un développeur choisi aléatoirement dans l'équipe de développement car il est toujours excitant de présenter le fruit de notre labeur en tête à tête avec le principal concerné. Souvent cette démonstration suit un chemin déjà établi et liés aux fonctionnalités développés : la personne faisant la démo prendra soin de vérifier que tout fonctionne pendant la passe qualité.
La démonstration est souvent l'occasion de se rendre compte que certains comportement du produit sont perfectibles et de créer des nouvelles US à intégrer dans le backlog.
Rétrospective
La rétrospective est un moment (une heure en général) passé avec l'équipe entière ou chacun peut exprimer ce qu'il a pensé en négatif ou en positif du sprint passé.
On pourrait écrire des livres entiers sur les différentes façons de faire cet exercice mais nous avons pour l'habitude de le faire avec des post-its :
- Pendant 10 minutes tout le monde prépare des post-its correspondant à ce qu'il souhaite partager,
- Puis chacun les restitue devant l'équipe (il présente chaque post-it mais ce n'est pas encore un moment d'échange). Si la même idée à déjà été exprimée, on empile le post-it.
- Puis on sélectionne les 3, 4 ou 5 piles négatives les plus imposantes et l'équipe échange ensemble sur les différentes axes d'améliorations possibles pour corriger cette situation.
- Puis on détermine et planifie des actions concrètes à mettre en place.
Cet exercice est présidé si possible par une personne extérieure au projet afin d'avoir un point de vue le plus neutre possible et de faire office de juge de paix si nécessaire.
Pour ceux qui n'aiment pas dépenser du papier, il est possible d'utiliser (comme nous) une extension intégrée à Azure Dev Ops : Retrospectives.

Rétro-code-spective
Les rétrospectives commencent à être un outil bien connu mais je trouve que cela n'est pas forcément le bon moment pour parler de code. On parle surtout d'organisation, de communication, de process, etc. mais rarement de problèmes techniques rencontrés. Pour pallier à ce défaut, nous avons l'habitude d'organiser des retro-code-spectives : exactement le même principe qu'une retrospective mais orienté code uniquement.
Le rendu de cette réunion d'environ une heure est souvent une liste de Technical Stories priorisées avec une estimation macroscopique du temps de réalisation. Cela permet ensuite d'échanger avec le PO pour planifier dans un sprint la mise en place de ces améliorations de la base technique du projet.
Il ne va pas sans dire que cela ne doit pas être le seul moyen d'améliorer techniquement le produit mais c'est un moment sacralisé pour prendre le temps de se poser sur les problématiques que chacun peut rencontrer.
Quelques exemples de points remontés lors de cet exercice :
- Les builds mettent troooppp longtemps à s’exécuter.
- Cette classe a beaucoup trop de responsabilité et devient beaucoup trop grosse/complexe.
- Débugger un bug de prod est beaucoup trop compliqué et fastidieux : il faut s'outiller.
- Beaucoup de bugs sont remontés sur cette fonctionnalité "X" : comment tester automatiquement pour éviter des régressions ou de nouveaux bugs ?
- etc.
Axes d'améliorations possibles
Je n'ai pas encore trouvé de manière efficace d'indiquer qu'une fonctionnalité doit être terminée avant de pouvoir en commencer une autre et de le prendre en compte dans le calcul de la capacité des développeurs : en connaissez vous une ?
Conclusion
Cet article n'est évidemment pas LA seule méthode à suivre et ce n'est même pas du tout celle que nous appliquons à la lettre sur chacun de nos projets mais je trouve que cela donne certaines pistes pour mettre en place le process qui correspond le mieux à votre équipe et votre besoin.
Qu'en pensez-vous ?


Commentaires