
Classifier des images avec TensorFlow
TensorFlow est la librairie de Google qui permet d'entrainer des modèles pour mettre en place le Machine Learning.
Parmi les fonctionnalités proposées, il est possible de faire de la classification d'images, qui peut être utilisée pour différencier des images entre elles, et c'est ce que nous allons voir dans cet article.
Les modèles de Machine Learning utilisés pour la reconnaissance d'images ont des millions de paramètres possibles : couleur, forme, taille, modèles, etc. Mettre en place cette technique "from scratch" nécessite une quantité de données importante et de nombreuses heures de traitement (souvent réalisé via la GPU) pour disposer d'un modèle vraiment efficace. Pour éviter cela, il est possible d'utiliser la technique du "Transfer Learning", à savoir la possibilité de s'appuyer sur un modèle existant pour, au final, l'étendre et lui apprendre à reconnaitre ce dont vous avez envie. Il existe différents modèles existants pour faire de la classification d'images, tel que Inception V3 et c'est celui que nous allons utiliser dans cet article :
![]()
Cela offre un avantage certain quand vous souhaitez reconnaitre des images "connues" (type de véhicule, type de fruits, etc.) mais quand vous avez vos propres besoins, cela n'est pas forcément pertinent donc à vous de décider si vous devez partir de 0 ou partir d'un modèle prédéfini.
Installation
La première étape consiste à installer Python 3.6, en version 64bit (la page d'installation est ici). Il existe des versions plus récentes de Python bien entendu mais TensorFlow n'est pas encore supporté avec ces versions.
Une fois Python installé, vous pouvez passer à l'installation de TensorFlow à proprement parler. Pour cela, une petite ligne de commande suffit:
pip3 install --upgrade tensorflow
Il existe 2 versions de TensorFlow: la version CPU et la version GPU, qui permet d'exploiter les capacités de votre GPU pour entrainer votre modèle. Ayant une Surface Pro 4, j'ai pris la version CPU :)
Entrainement du modèle
Pour créer / entrainer notre modèle, nous allons nous appuyer sur un script python pré-existant et téléchargeable ici : https://github.com/tensorflow/hub/raw/master/examples/image_retraining/retrain.py
Placer ce fichier dans un répertoire et, à côté, créer un répertoire "training_data", qui contiendra les images de départ que vous allez utiliser pour entrainer votre modèle:

Comme indiqué, c'est dans ce répertoire que vous devez mettre vos images de référence mais vous devez les classer dans des sous-répertoires correspondant à ce qu'elles représentent. Dans mon cas, je peux identifier si un pouce est levé (High) ou s'il est bas (low) donc j'ai créé 2 répertoires correspondant dans lesquels j'ai mis mes images de départ :
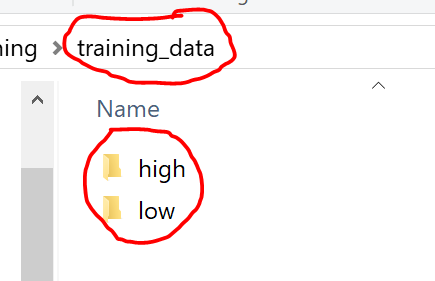
A noter : pour bien fonctionner, il est recommandé d'utiliser une centaine d'images (minimum) par "catégorie". Cela peut paraitre beaucoup mais c'est ce qui permettra à votre modèle d'être le mieux entrainé possible.
Vos images étant prêtes, il ne vous reste plus qu'à entrainer le modèle, au moyen du script téléchargé précédemment :
python retrain.py --how_many_training_steps 4000 --output_graph=./retrained_graph.pb --output_labels=./retrained_labels.txt --image_dir=./training_data --summaries_dir=./logs
Ce script prend en paramètres :
- how_many_training_steps : le nombre de "steps" qui doivent être réalisés pour entrainer le modèle (plus on entraine, mieux c'est mais, à un moment, cela ne sert plus à rien, il vaut mieux jouer sur le nombre d'images ou la distortion)
- output_graph : le chemin vers le modèle qui sera créé
- output_labels : le chemin vers le fichier qui contiendra la liste des labels (catégories) identifiés lors de l'entrainement
- image_dir : l'emplacement vers les fichiers d'entrainement
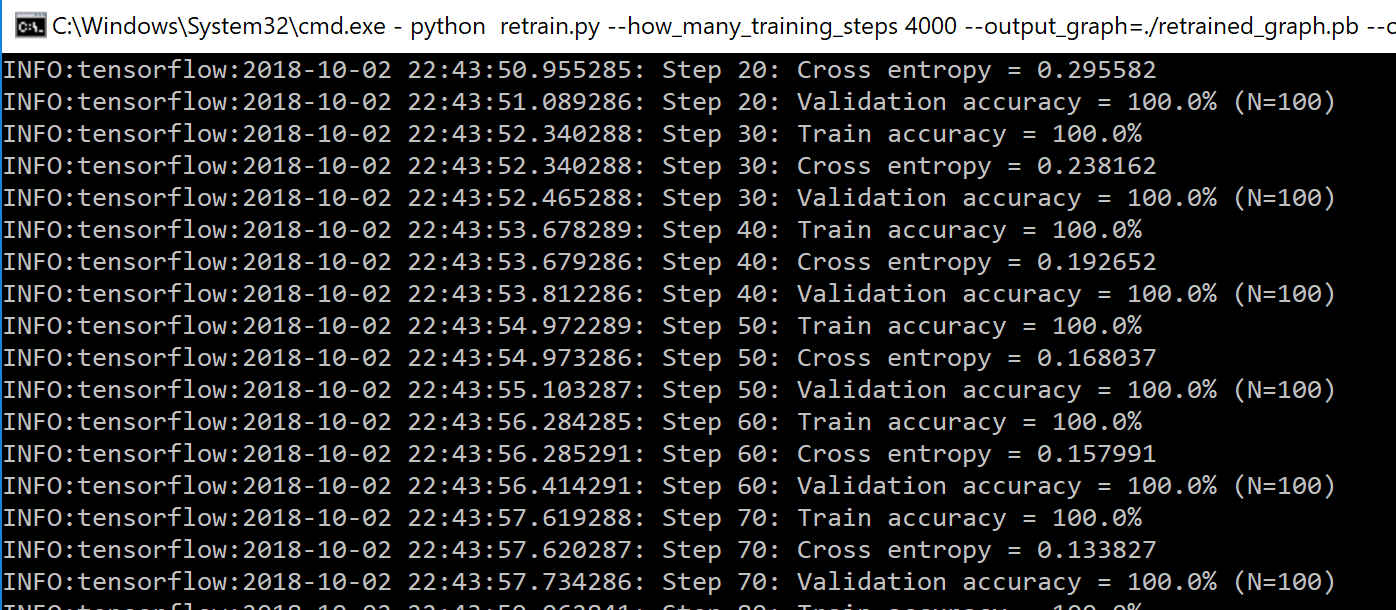
Lors de l'exécution, vous verrez différentes valeurs apparaitre :
- Train accuracy : Représente le pourcentage d'images de départ qui ont été correctement catégorisées
- Validation accuracy : Précision (pourcentage d'images correctement catégorisées) sur un groupe d'images sélectionnées de manière aléatoire
- Cross entropy : Fonction qui donne un aperçu de la progression du pourcentage d'apprentissage (plus les chiffres sont bas, mieux c'est)
A la fin de l'entrainement, le fichier correspondant au modèle (retrained_graph.pb) est généré et prêt à être utilisé :
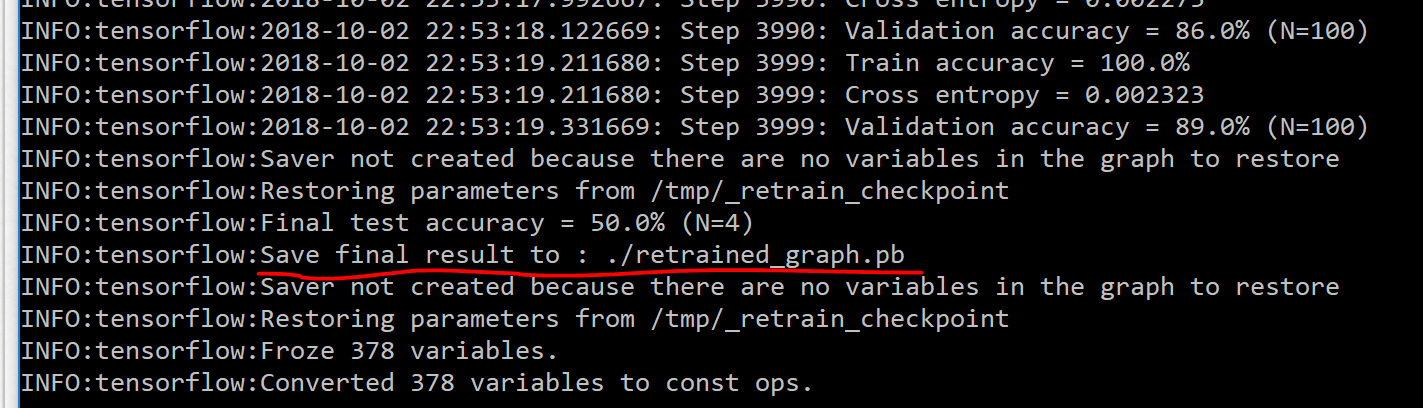
Au passage, on notera que disposant seulement d'une vingtaine d'images de chaque catégorie, mon modèle ne sera efficace qu'à 50%
Visualisation de l'entrainement avec TensorBoard
Grâce à l'utilisation du paramètre "summaries_dir", il est possible d'utiliser l'outil TensorBoard pour visualiser la courbe d'apprentissage du modèle :
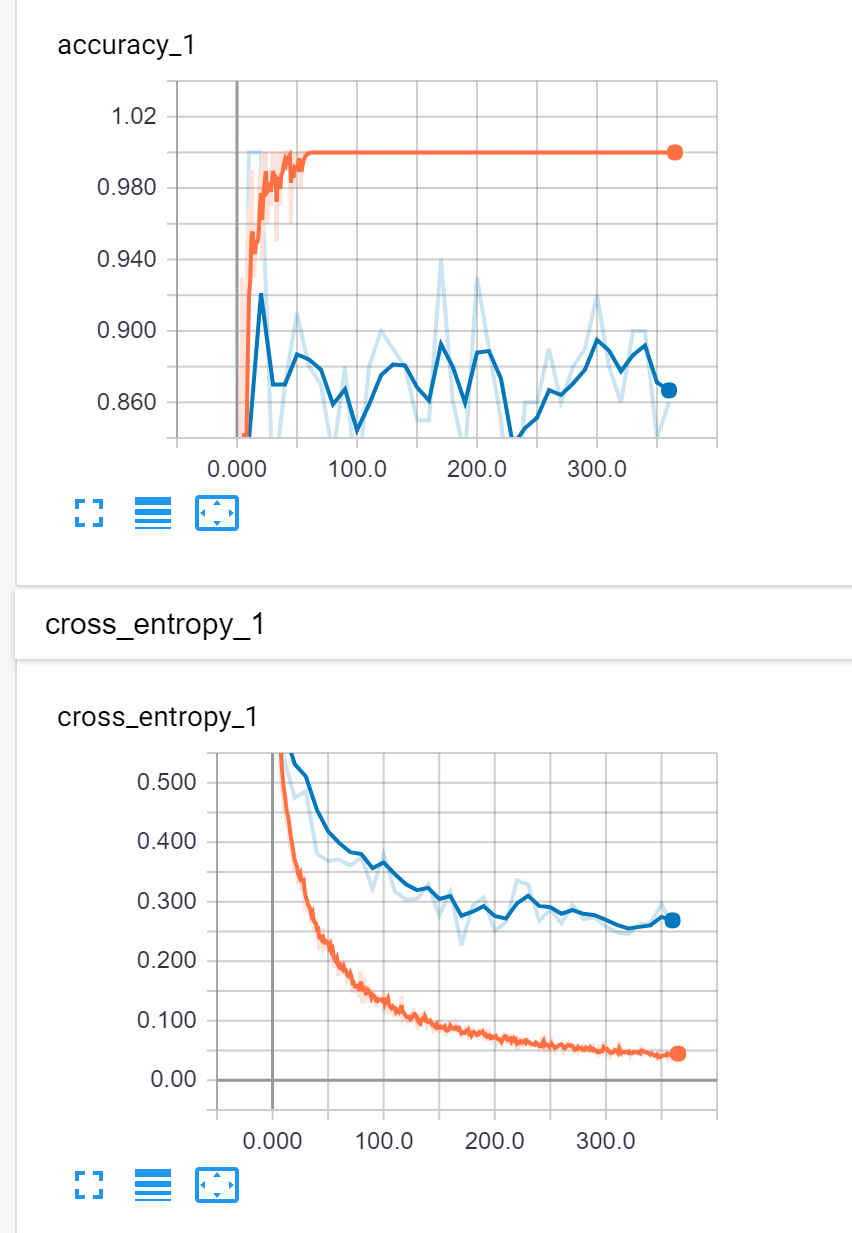
Etant donné que l'entrainement du modèle peut prendre un certain temps (en fonction des capacités de votre machine), cet outil graphique s'avère très pratique pour visualiser l'avancement de l'apprentissage, ainsi que les différentes phases effectuées.
Utilisation du modèle
Le modèle étant maintenant entrainé, nous pouvons l'utiliser pour valider la classification d'une image. Pour cela, nous allons la-encore utiliser un script Python déjà existant et disponible à l'adresse suivante : https://github.com/tensorflow/tensorflow/raw/master/tensorflow/examples/label_image/label_image.py
Voici la ligne de commandes à utiliser :
label_image.py --graph="retrained_graph.pb" --labels="retrained_labels.txt" --input_layer=Placeholder --output_layer=final_result --image="photo.jpg"
Comme vous pouvez le constater, on passe en paramètres le modèle (retrained_graph.pb), la liste des catégories qu'il connait (retrained_labels.txt) et on attend le résultat :

Comme on peut le constater, les données ne sont pas très probantes donc voyons comment améliorer le modèle malgré le peu d'images de départ dont je dispose.
Amélioration du modèle
Pour améliorer le modèle, vous pouvez augmenter le nombre de steps (how_many_training_steps). Cette valeur est à 4000 par défaut mais voici les valeurs obtenues lorsque l'on joue un peu avec :
- how_many_training_steps à 8000 :
- high: 0.7911934
- low: 0.20880659
- how_many_training_steps à 16000 :
- high: 0.8214073
- low: 0.17859274
- how_many_training_steps à 64000 :
- high: 0.86995536
- low: 0.13004468
Attention, plus vous augmentez cette valeur, plus les temps d'apprentissage seront longs! Et, au bout d'un moment, vous n'obtiendrez pas de meilleurs résultats donc vous pourrez, à ce moment, utiliser le paramètre learning_rate, qui correspond à la fréquence du taux d'apprentissage du modèle.
Enfin, vous avez beau jouer sur la durée et le taux d'apprentissage, si vous n'avez pas assez d'images, cela ne servira à rien. Etant donné qu'il n'est pas toujours possible d'avoir une grande quantité d'images de départ, le script retrain.py dispose de paramètres tels que random_crop, random_scale et random_brightness qui permettent d'appliquer des effets visuels (distortion, agrandissement/réduction, changement de luminosité, etc.) sur les images, augmentant de cette manière le nombre d'images utilisées pour le training du modèle. Attention cependant, l'utilisation de ces paramètres entraine des temps d'apprentissage beaucoup plus longs !
Voilà, je pense avoir fait le tour! Il est bien sûr possible d'aller beaucoup plus loin, d'utiliser d'autres modèles de base, etc. mais ce sera peut-être pour une prochaine fois :)
Une chose est sûre, mon prochain article expliquera comment faire la même chose mais en utilisant les Cognitive Services de Microsoft et l'API Custom Vision : stay tuned!
D'ici là, si vous souhaitez en savoir plus, vous pouvez vous rendre ici.
Happy coding!

Commentaires