
Quelle est la différence entre le bon et le mauvais développeur Cloud ?
Le mauvais développeur Cloud, il fait une archi, il code proprement et il optimise.
Le bon développeur Cloud, il fait une archi, il code proprement, il optimise, mais c’est un bon développeur Cloud.
Passé cette référence aux années 80, voici mon point de vue sur un élément souvent oublié… le coût ! $ € £
En effet, lorsque l’on met en place une architecture Cloud, il est primordial de prendre en considération une donnée supplémentaire : le coût des ressources.
Fusion des équipes
Dans le passé, un architecte concevait une architecture logique, la transformait en architecture physique afin d’aider les équipes IT/Infra de production à dimensionner et préparer les environnements d’exploitations requis. La responsabilité du coût d’exploitation était portée uniquement par l’équipe Infra, qui optimisait le budget global d’hébergement en mutualisant des applications.
Sur inwink, en tant qu’éditeur de solution SaaS ayant fait le choix du Cloud, nous ne séparons plus les rôles de développeur / administrateur système : la gestion de la production est assumée directement par l’équipe de développement.
Prise en compte du coût de ressource Cloud
L’équipe de développement étant responsable du bon fonctionnement de la production, il en ressort pour moi deux responsabilités qui incombent à un bon développeur / architecte Cloud :
- Faire les bons choix de services, dans la conception de l’architecture, pour anticiper le coût
- Chercher à optimiser la consommation de ressources en production, au même titre que les performances
Il est donc important que chaque développeur de l’équipe soit conscient des coûts associés à la production. La facture Cloud n’est plus une donnée confidentielle et doit être partagée chaque mois avec l’ensemble de l’équipe.
Le coût de notre infrastructure mensuelle est d’ailleurs présent sur nos tableaux de monitoring de production, au même niveau que nos indicateurs de performance (CPU, temps de réponse moyen…) - accessible à tous en temps réel.
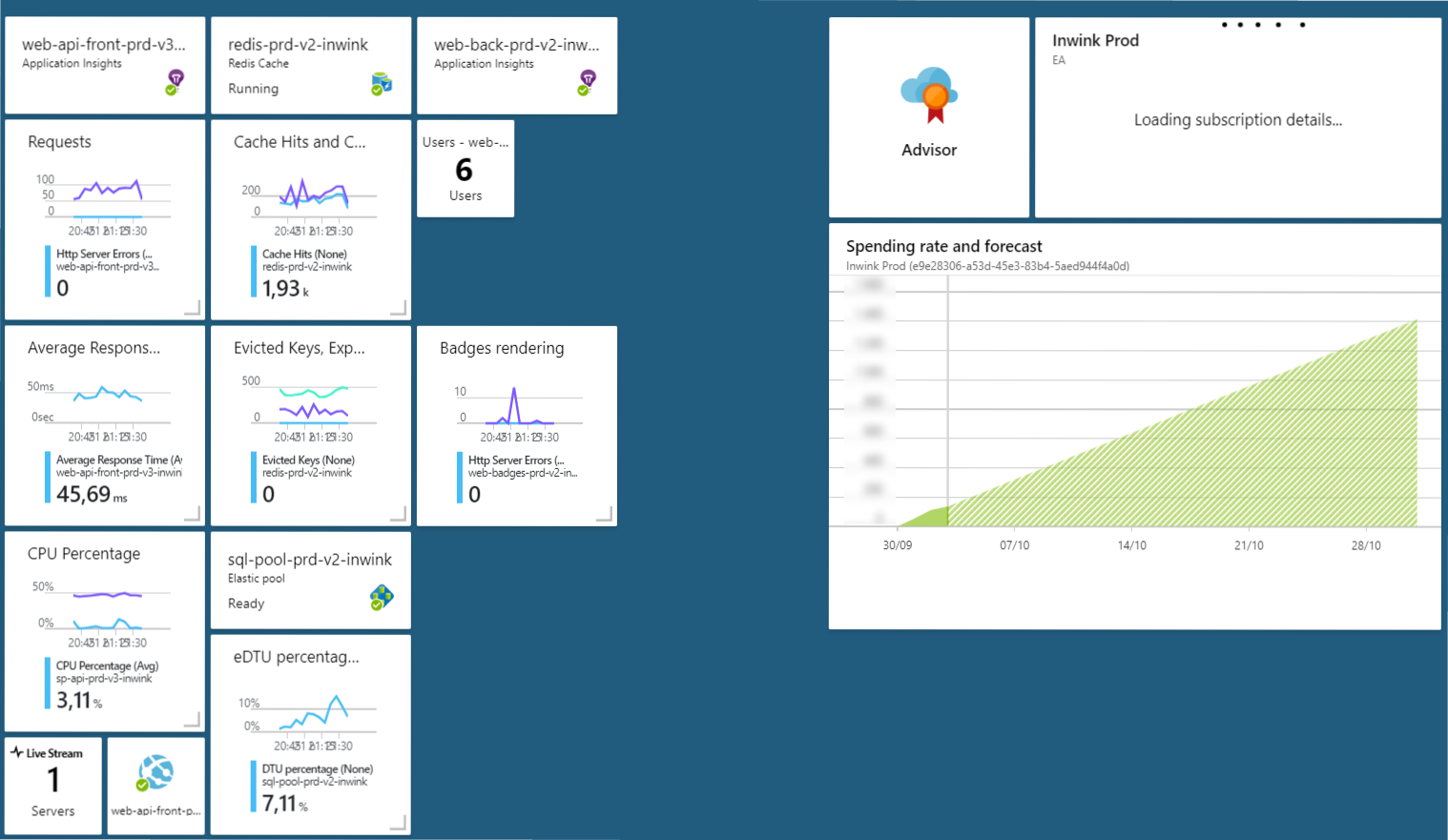
Avant tout développement : les bons choix de services Cloud
L’idée n’est pas de comparer les coûts de AWS vs Azure vs Google Cloud, ce choix peut souvent être stratégique et ne doit pas forcément influer sur le développement.
Dans notre cas, nous avons fait le choix d’utiliser Microsoft Azure, par affinité technologique et surtout par rapport à l’offre de services PaaS que Microsoft propose. Notre objectif est de disposer d’environnements de production à quasi-majorité PaaS pour justement éviter de devoir transformer notre équipe en administrateurs de machines IaaS. (PaaS vs IaaS)
Mais depuis 3 ans qu’inwink a démarré sur Azure, nous avons toujours challengé les choix architecturaux en prenant en considération si tel ou tel service, en plus de nous faire gagner du temps, va être sur-coûteux sur du long terme.
Quelques exemples :
Sur les bases de données :
- Nous avions besoin de bases de données SQL Server, en garantissant une isolation des données par client / événement.
- Il y a 3 ans, dans Azure, le coût était « à la base de données ». Afin de ne pas payer une base de données par client tout en garantissant une bonne isolation des données, nous avons fait le choix dès le début de mettre en place une politique de sharding (avec RLS) pour limiter le nombre de bases de données.
- Avec les évolutions d’Azure il y a 2 ans, et la possibilité de créer des pools de base de données en mutualisant le coût des bases de données, nous avons pu faire évoluer ce modèle.
Sur l’exposition et la documentation d’API :
- Microsoft propose depuis plusieurs années un service, API Management, qui permet de proxifier automatiquement les APIs en générant documentation, caches, statistiques et jetons d’accès sécurisés.
- Très tentant quand on commence une nouvelle architecture car cela peut faire gagner beaucoup de temps.
- En tant que développeur geek, nous avons tout le temps envie d’utiliser les nouveautés. Ici, nous avons écarté ce choix structurant en analysant le coût sur du long terme (quelques 100aines d’euros / mois).
- Après 3 ans, nous ne le regrettons pas, car nous aurions créé de la dépendance avec un service qui ne nous aurait finalement pas apporté grand-chose.
Sur la gestion de cache distribué :
- Nous avions besoin de mettre en place une stratégie de cache distribué
- Après plusieurs études, notamment l’évaluation de l’utilisation d’un serveur IaaS vs du Redis as a Service, nous avec fait le choix d’utiliser la version PaaS de redis proposée par Microsoft, toujours en comparant ce que nous coûte ce service vs ce qu’il nous rapporte par mois
- Une bonne utilisation de ce cache divise quasiment par 4 le nombre de machines nécessaires à l’absorption des pics de charge, ce qui permet un très bon retour sur investissement.
Pour chaque évolution de l’architecture applicative, le coût des nouvelles ressources et services utilisés est donc systématiquement challengé :
- Avons-nous vraiment besoin de ce service ? (car il est souvent difficile de se séparer d’un service une fois en production)
- Combien va-t-il nous coûter chaque mois VS que va-t-il nous faire économiser (du temps, de la ressource système ?)
Bref, nous, développeurs, nous devons maîtriser nos choix.
Après le développement : l’optimisation permanente
Une fois en phase de production, le travail d’optimisation de coût doit être permanent et doit faire partie des analyses quotidiennes, avec la même importance que l’analyse et l’amélioration des performances.
Lorsque j’ai commencé à développer, comme tout développeur fainéant, la stratégie à mener lorsque l’on se rendait compte que nos applications ramaient en production était de demander aux Administrateurs Systèmes d’augmenter la taille des machines, ou d’en ajouter – facile – nous l’avons tous fait.
Et quand on est réaliste, il n’est pas normal d’utiliser des machines à 16 cœurs pour faire tourner des bases de données dédiées à 10 utilisateurs, ni d’utiliser 4 frontaux webs derrière un load balancé pour un site web délivrant une 100aine de requêtes par seconde… le problème vient souvent du code, pas de l’infrastructure.
Dorénavant, en étant responsable de l’exploitation de ce que l’on produit, avant d’augmenter la taille des ressources dans le Cloud, nous nous retrouvons obligés de chercher :
- Qu’est ce qui consomme des ressources ?
- Est-ce qu’il est possible d’optimiser le code plutôt que d’augmenter les ressources ?
Il est vraiment primordial de sensibiliser chaque développeur sur ces questions, car il est encore plus simple aujourd’hui qu’hier, en Cloud, d’upscaller horizontalement ou verticalement des ressources. Avec le Cloud, il suffit d’un clic et de quelques secondes pour transformer un mono serveur 1 cœur à une 20aine de serveurs 16 cœurs, voir même sans clic en configurant de l'autoscalling.
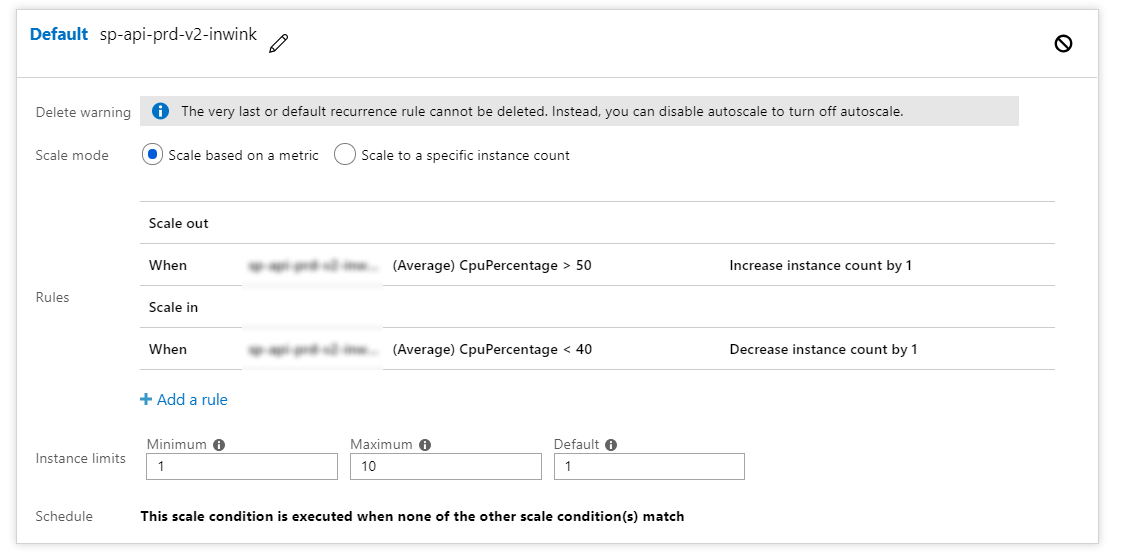
De plus, les plateformes de Cloud proposent maintenant beaucoup d’outils pour comprendre en temps réel ce qui consomme de la ressource à mauvais escient : du machine learning pour positionner automatiquement des index SQL aux outils de profiling et d’instrumentation temps réel tournant directement sur les environnements de production.
Quelques exemples :
Sur la surveillance des ressources :
- Séparer et regrouper les ressources sur différents serveurs en fonction de la charge de chacun. Dans notre cas, nous avons par exemple un micro service chargé de générer les badges PDF qui est extrêmement coûteux en CPU. Il est donc isolé sur un lot de machines dédié pour ne pas impacter d’autres ressources et coûter cher pour une utilisation rare. Il est donc devenu primordial de le réécrire pour réduire sa consommation et le remettre à côté des autres ressources.
Sur le profiling :
- Avec une analyse rapide, il est simple de voir les requêtes http les plus appelées, et avec l’instrumentation en production de voir, dans le code, quelles portions sont coûteuses en CPU, et donc en temps, et donc en coût !
Encore, sur la mise en cache :
- Avec du profiling, il est également aisé de détailler le chemin d’exécution de chaque requête http, et donc d’ajouter un cache efficace pour réduire les temps de réponse, limiter l’usage de CPU, et finalement permettre de traiter plus de requêtes avec moins de processeurs.
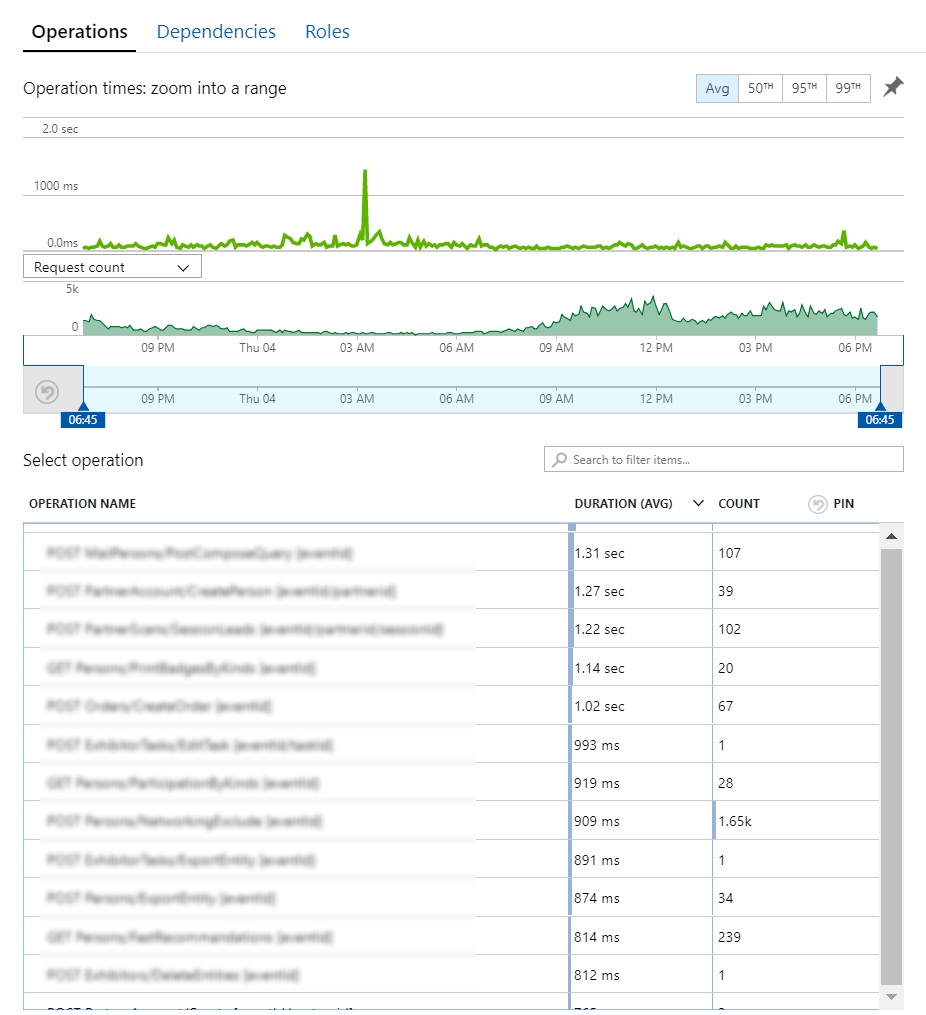
Bref, nous, développeurs, nous devons assumer les performances de notre code et comprendre l’impact d’un mauvais code sur la facture finale.
En conclusion !
La différence, pour moi, entre le bon et le mauvais développeur Cloud, c’est que le bon développeur Cloud, il écrit du code en ajoutant le coût aux objectifs de qualité, de maintenabilité et de performance.


Commentaires