
Introduction à Azure Elastic Db pool
Lors de la mise en place d’une application multi tenants utilisées par plusieurs clients indépendants, une bonne pratique consiste à créer une base de données par client.
L’utilisation de plusieurs bases de données apporte deux avantages majeurs :
- Les données sont segmentées physiquement
- Chaque base de données peut être dimensionnée et mise à l’échelle indépendamment
Cette multiplication des bases de données engendre cependant de nouvelles problématiques :
- Gestion de la charge
Chaque client va utiliser l’application SaaS de façon différente, provoquant des pics de charge plus ou moins importants à des moments différents : la stratégie de gestion de la charge va donc être différente pour chaque base de données. Même si Azure SQL Database est un service PaaS, il est nécessaire de surveiller l’utilisation de chaque base donnée pour s’assurer que les ressources utilisables sont suffisantes, et plus le nombre de base de données augmente, plus cette phase de monitoring devient complexe.
2. Mise à jour des données et de la structure
Pour mettre à jour des données ou modifier le schéma de la base, il est nécessaire d’appliquer des scripts sur l’ensemble des bases, ce qui peut rapidement devenir chronophage si le nombre de base de données est important.
Dans cet article nous allons nous intéresser à la première problématique en utilisant une solution « built in Azure » nommée Elastic Db Pool. La seconde problématique peut être solutionnée en utilisant « Azure Elastic Job » et sera traitée dans un prochain article. Pour la simplicité de cet article nous utiliserons une application SaaS fictive nommée « SaaSapp » utilisée par 3 clients possédant chacun une base de données « customer1-db », « customer2-db », « customer3-db ».
Azure SQL Database : les bases
Niveaux de services et niveaux de performances :
Une mise à l’échelle verticale consiste à augmenter ou diminuer les ressources matérielles utilisables par la base de données. Avec Azure SQL Database, elle s’effectue augmentant ou en réduisant le nombre de DTU utilisable par la base.
Mise à l’échelle verticale = Ajout / Suppression de DTUs consommables par la base de donnée
Une mise à l’échelle horizontale consiste à augmenter le nombre de base de données pour répartir la charge. Pour effectuer ce type de mise à l’échelle, il faut lors de la phase d’architecture du projet définir le schéma de segmentation des données et utiliser des outils spécifiques comme Azure Elastic Scale.
Mise à l’échelle horizontale = Ajout de bases de données pour répartir la charge
Le schéma suivant illustre l’utilisation de plusieurs bases de données Azure SQL Database pour une application l’application « SaaSapp » :
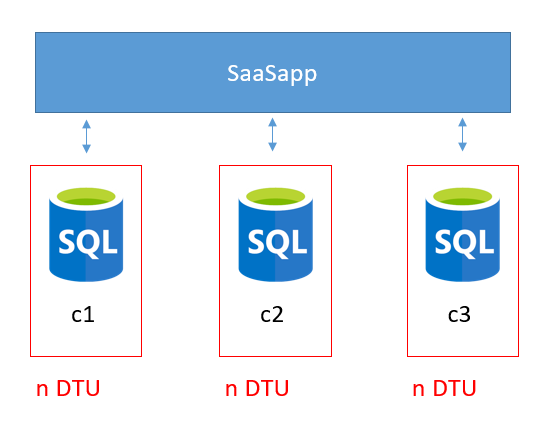
- Sur dimensionnement : Permet d’assurer une continuité de service optimale, mais cette solution est onéreuse, car elle revient à payer cher pour chaque base de données
- Sous dimensionnement : Solution économique mais qui peut s’avérer dangereuse en cas de forte charge car les performances peuvent s’avérer insuffisantes et entrainer une dégradation du service.
De plus, une question reste en suspens : Comment faire face efficacement aux pics de charges ? C’est là que le pool de base de données élastique intervient.
Elastic Pool Database : Partage des ressources
De plus, une question reste en suspens : Comment faire facUn pool élastique permet de mettre à disposition des ressources matérielles (CPU, Mémoire, I/O), non pas par une mais pour un ensemble de base de données. Un pool élastique permet donc à plusieurs bases de partager un nombre de DTU global nommé eDTU (Elastic Data Transaction Unit). e efficacement aux pics de charges ? C’est là que le pool de base de données élastique intervient.
Les eDTU fonctionnent avec les niveaux de services classiques (« Basic », « Standard » et « Premium ») qui permettent d’attribuer :
- Un nombre plus ou moins important d’eDTU au pool
- Des bornes de consommations pour chaque base de données *
- La quantité de stockage utilisable par le pool (en Go)
Par exemple : Un Pool « Standard » avec 50 eDTU permet à chaque base d’utiliser 50 eDTU, l’espace de stockage global du pool est 50 G0.
* « Des bornes de consommations pour chaque base de données »
Au sein du pool, chaque base de données possèdent des bornes de consommations : un minimum (qui peut être nul !) et un maximum qui doit être assez haut pour absorber les pics de charge (la documentation préconise de définir un maximum de 1.5 x la charge moyenne !).
[Warning] : Le maximum de eDtu utilisable par une base de donnée ne doit pas obligatoirement être configuré avec le maximum de eDtu utilisable au sein du pool, dans la mesure du possible il doit s’accorder avec les pics de charge de la base données. Il est même conseillé de ne pas permettre à l’ensemble des bases de données présentes dans le pool d’utiliser le maximum d’eDTU disponible dans le pool, de façon à éviter qu’une seule base accapare l’ensemble des eDTU disponibles.
Le schéma suivant montre l’utilisation de 3 bases de données, regroupées aux seins d’un pool : 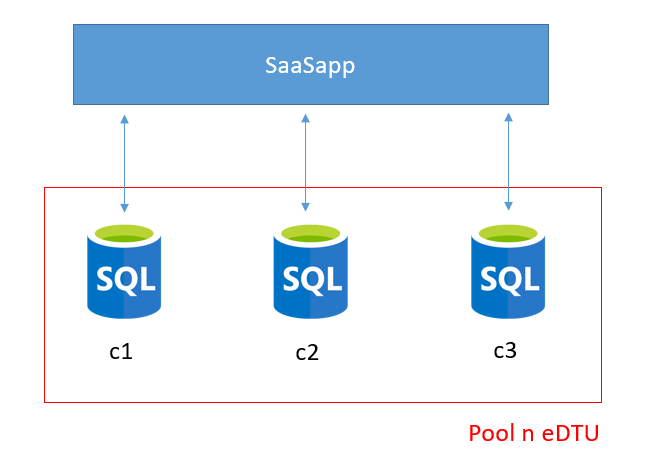
Mise en situation avec un niveau de service « Standard » :
Un pool configuré avec un niveau de service Standard et 50 eDTU coûte environ 95 € / mois. Si le pool est configuré pour que chaque base puisse utiliser entre 0 et 50 eDTU, le pool peut contenir au maximum 100 bases de données.
Peu importe le niveau de service utilisé, il primordial de prendre en compte les moments ou les pics de charge surviennent, de façon à ce que les bases de données puissent utiliser le maximum de ressource nécessaire sans impacter les performances des autres bases ! Il n’est en effet pas possible que plusieurs bases de données utilisent en même temps la totalité de eDTU du pool.
Mise en place et configuration
Pour l’exemple nous allons créer un pool qui regroupera 3 bases de données. Nous allons utiliser des commandes Azure CLI, utilisables directement dans le Cloud Shell Azure.
1. Création du groupe de ressource « data-rg » :
az group create -l westeurope -n data-rg
2. Création du serveur de base de données :
az sql server create -g data-rg -n saasappsrv -l westeurope -u adminsvr -p TranisePwd11
3. Création du pool de base de donnée « saasappdbpool » :
az sql elastic-pool create -g data-rg -n saasappdbpool -s saasappsrv –-edition Standard --db-min-dtu 0 --db-max-dtu 50
Lors de la création d’un pool, il faut spécifier au minimum:
- Le serveur sql lié au pool
- Une édition : Le niveau de service
- Le nombre de eDTU minimum et maximum utilisable par chaque base de données
Dans l’exemple, on utilise une édition « Standard » qui octroie 50 eDTU au pool et une taille maximale de 50 GO. Nous voulons que chaque base de données puisse utiliser le maximum de eDTU disponible soit 50 eDTU.
4. Création des 3 bases en les ajoutant dans le pool précédemment crée :
az sql db create -g data-rg -n customer1-db -s saasappsrv --elastic-pool saasappdbpool az sql db create -g data-rg -n customer2-db -s saasappsrv --elastic-pool saasappdbpool az sql db create -g data-rg -n customer3-db -s saasappsrv --elastic-pool saasappdbpool
Une fois cet ensemble de commande exécuté, le groupe de ressource « data-rg » est accessible dans le portail Azure :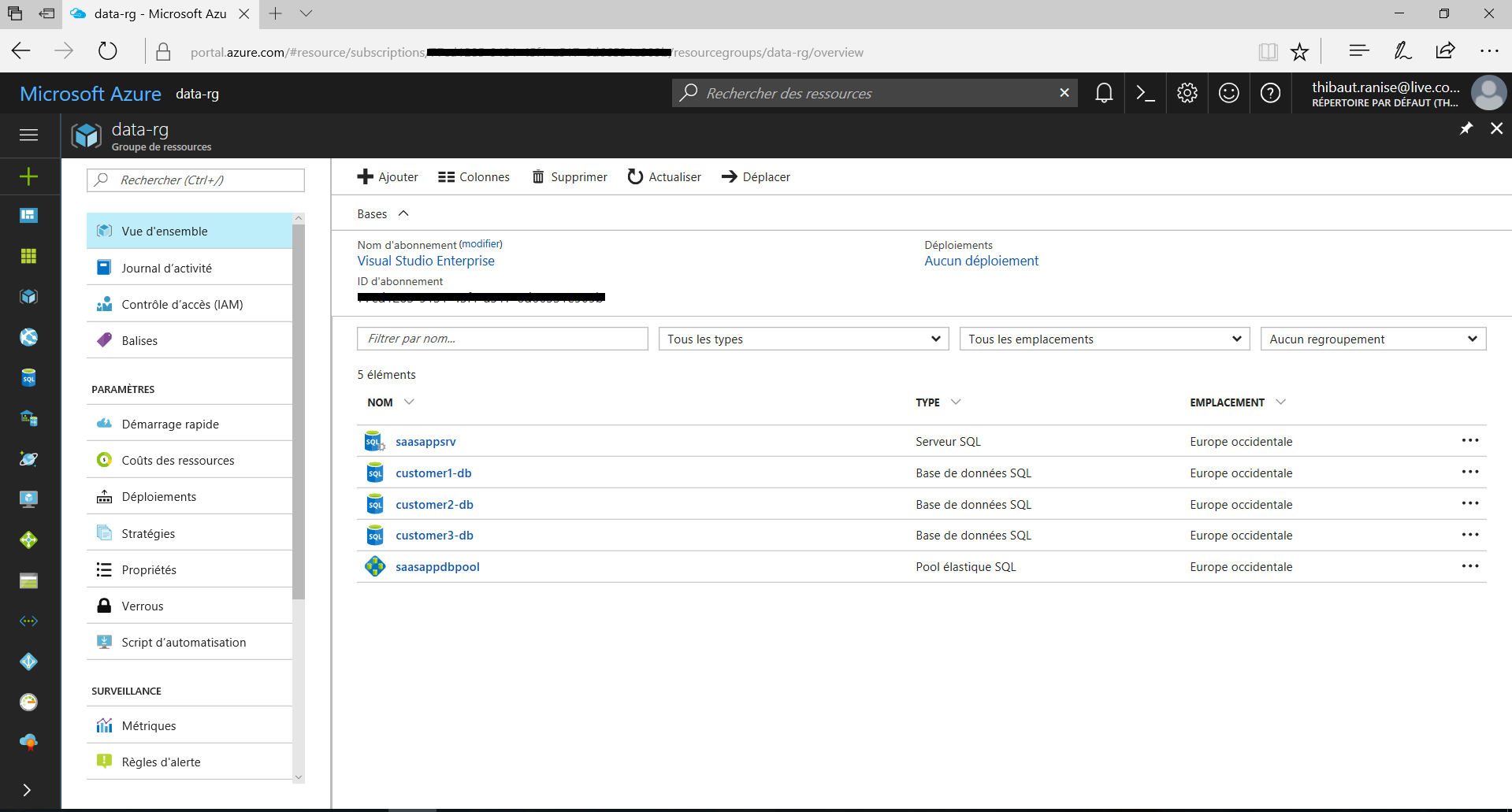
Sur la vue de détails du pool, on découvre deux graphiques de monitoring (expliquées dans la section suivante) et il est possible de configurer le pool directement depuis le menu de gauche « Configure pool » :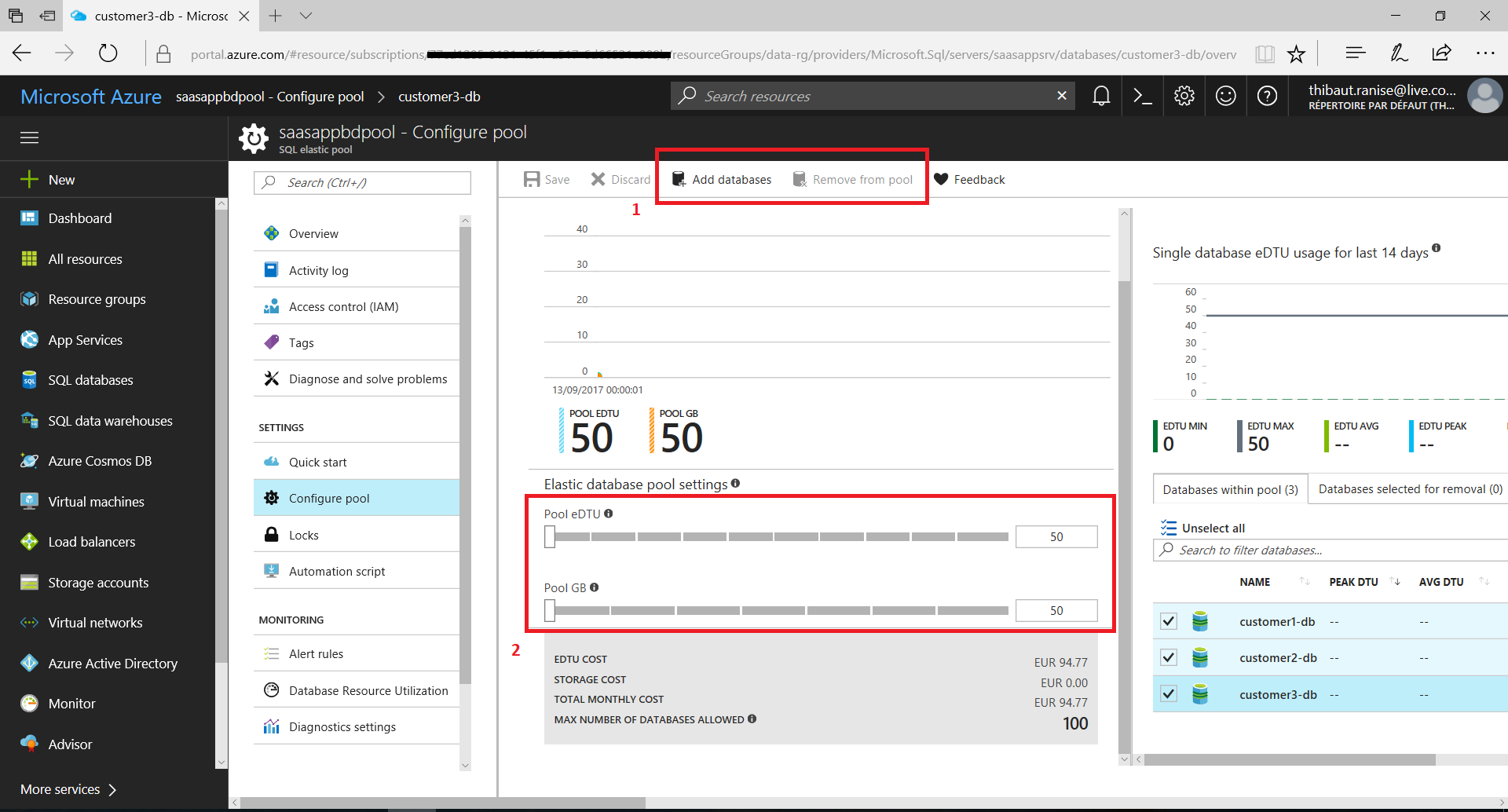
Sur cet éran de configuration il est possible :
- D’ajouter et de supprimer des bases de données du pool
- De mettre à l’échelle le pool (augmenter / diminuer le nombre de eDTU ainsi que la capacité de stockage du pool)
Monitorer son pool
Les bases de données Azure SQL étant des services PaaS, Microsoft fournit automatiquement des données de monitoring de l’utilisation des bases de données. Cela permet de surveiller l’utilisation des bases et d’envisager des opérations de mise à l’échelle si nécessaire.
Le portail Azure met à disposition des graphiques qui permettent d’exploiter ces données de monitoring. Ces derniers remontent les données présentes dans des vues sql stockées dans la base de données « Master » du Serveur : Les DMV pour « Dynamic Managment Views ».
La consommation des ressources matérielles d’une base de données Azure sont stockées dans une vue nommée « sys.dm_db_resource_stats ». Les données de télémétries présentes dans cette vue sont exprimées en pourcentage où 100% correspondant à la limite maximale autorisé par le plan de service de la base (Max DTU). Cette vue permet également de monitorer l’utilisation d’une base présente dans un pool, les pourcentages exprimés sont alors calculés par rapport à la limite maximale autorisée par le plan de service du pool (Max eDTU).
Intérêts financiers et techniques
Plus les bases de données utilisent des niveaux de service important, plus l’utilisation du pool est intéressante financièrement. Par exemple, un pool élastique Standard 50 eDTU coûte environ 95 € / mois et il peut contenir au maximum 100 bases de données.
Sans utiliser de pool, voici le prix unitaire des bases de données « Standard » :
- Une base SQL Azure Standard S1 coute environ 25 € / mois et permet à chaque base d’utiliser 20 DTU
- Une base SQL Azure Standard S2 coute environ 62 € / mois et permet à chaque base d’utiliser 50 DTU
4 x 25 (niveau de service Azure SQL Standard S1) = 100 > niveau de service Standard 50 eDtu d’un pool élastique = 95
2 x 62 (niveau de service Azure SQL Standard S2) = 124 > niveau de service Standard 50 eDtu d’un pool élastique = 95
L’intérêt technique est lui présent à partir du moment où deux bases sont présentes dans le pool ! Il permet à chaque base de données du pool de faire face aux pics de charge beaucoup plus facilement. De plus un pool permet à des bases de données d’attendre des niveaux de performances non proposés par les niveaux de services classiques : par exemple aucun niveau de service classique ne permet à une base de données d’utiliser 300 DTU, ce qui est réalisable au sein d’un pool. Enfin, un pool élastique permet de mettre en place facilement l’infrastructure nécessaire à l’utilisation des Jobs élastiques que nous détaillerons dans un prochain article… !
Pour approfondir ce sujet, un chapitre sur les bases de données Azure SQL Database est disponible dans notre livre. D'ailleurs, jusqu'au 22 septembre, vous pouvez tenter de gagner notre livre en participant à ce tirage au sort. Bonne chance !

Happy coding :)

Commentaires