
♫ tout tout ♫ vous saurez tout sur git ♫ partie 3
Après avoir évoqué différents aspects de GIT dans deux précédents articles (ici et là) et en avoir exploré les bases via Team Explorer et la ligne de commande, nous allons maintenant nous attarder sur l'utilisation des branches.
Gestion des branches
Commençons par le début : qu’est-ce qu’une branche ? On en retiendra qu’il s’agit d’un moyen de faire diverger le code source en deux ou plusieurs versions différentes. En effet, si l’on se représente l’historique des modifications du code comme un arbre, où chaque commit serait un nœud de celui-ci, une branche démarrerait au niveau d’une intersection. On imagine généralement une branche principale (communément nommée master) dont partiraient d’autres branches. Ainsi, une fois les branches créées, il est possible de faire évoluer le code différemment dans celles-ci. Cela permet de mettre en place toute sorte de scénarios, aussi bien d’un point de vue collaboratif, où une équipe pourrait travailler sur une branche dédiée d’un projet afin de ne pas impacter l’autre équipe qui travaillerait sur une autre branche, que d’un point de vue pratique, puisque cela peut aussi permettre de développer une fonctionnalité et de la garder isolée dans une branche tant qu’elle n’est pas terminée. Evidemment, à un moment donné, il est souvent nécessaire de faire fusionner deux branches afin de bénéficier des modifications de l’une dans l’autre : on parle alors de merge de branche.
Comme on peut s’en douter, GIT offre des fonctionnalités permettant de gérer des branches de code, c’est d’ailleurs souvent l’un des principaux atouts qu’on évoque lorsque l’on en parle.
Créer une branche locale
Comme de coutume avec GIT, nous commençons généralement par travailler sur notre repository local, avant de le synchroniser avec un serveur. Nous allons donc voir comment, à partir d’une branche existante, en créer une nouvelle. Pourquoi partir d’une existante si vous n’en n’avez jamais créé ? Tout simplement parce que par défaut, lorsqu’un repository est créé, il contient une unique branche nommée master sur laquelle nous travaillons sans forcément nous en rendre compte.
Team Explorer
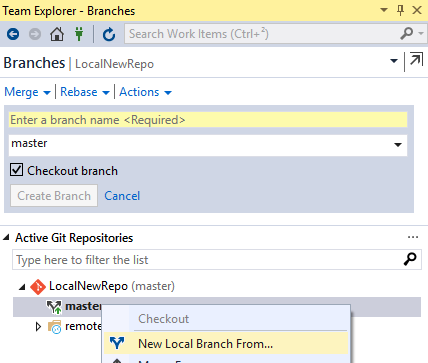
Dans la section « branches » de Team Explorer, vous pourrez lister les branches existantes. Un clic droit sur l’une d’entre elle (« master » par exemple) donne la possibilité de créer une branche locale à partir de la cible. Une fois nommée, et la case « checkout » cochée ou non (ce qui permettra de basculer automatiquement sur la nouvelle branche ou non), valider avec le bouton « Create Branch » créera la branche et celle-ci sera tout de suite exploitable.
Command Line
Pour créer une branche en ligne de commande, il faut utiliser l’action « branch », suivi du nom de la branche :
git branch <branch_name>
Ainsi, une branche est créée, sur la base de la branche courante. Ce qui signifie que la nouvelle branche est pour le moment dans le même état que celle sur laquelle on se trouvait au moment de la création. Pour basculer sur la nouvelle branche (ou une autre) :
git checkout <branch_name>
Il est ensuite possible de travailler dans la nouvelle branche sans plus de manipulations. Les nouveaux commits seront directement intégrés à la branche sélectionnée via l’opération checkout.
Il est aussi possible d’utiliser l’option -b de la commande checkout pour automatiquement basculer sur une nouvelle branche à sa création (en une seule étape) :
git checkout -b <branch_name>
La commande branch permet aussi de créer une branche à partir d’un état donné (plutôt que du courant) en spécifiant un dernier argument :
git branch <branch_name> <id>
Ici, id peut être remplacé par un id de commit, le nom d’une autre branche ou encore un tag.
Publier une branche
Pour le moment, une branche créée à partir de Visual Studio ou en ligne de commande n’est accessible que sur la machine courante. Pour la partager avec une équipe par exemple, il faut la publier sur le serveur.
Team Explorer
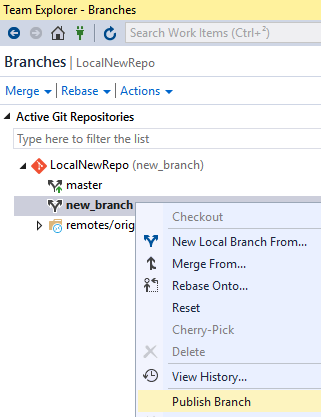
L’option « Publish Branch » du menu contextuel peut aussi se nommer « Push Branch » selon la version de Visual Studio utilisée.
Command Line
En ligne de commande, il faut utiliser l’argument « --set-upstream » (abbrégé par « -u ») pour publier la branche locale souhaitée :
git push –u origin <branch>
Le mot clef « origin » représente ici la remote voulu, soit le nom courant pour le serveur distant sur lequel on souhaite publier la branche. Git permet bien sûr d’utiliser un même repository local et de le connecter sur différents repository maître possible, chacun représenté par une remote différente.
Obtenir une branche
Lorsqu’une nouvelle branche est publiée depuis un autre poste, il se peut que celle-ci ne soit pas visible. Pour remédier à cela, il suffit d’utiliser la commande fetch.
Team Explorer
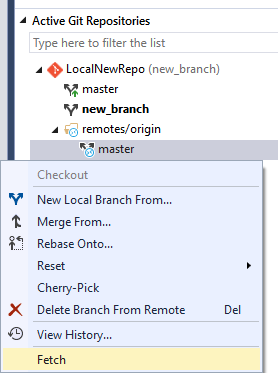
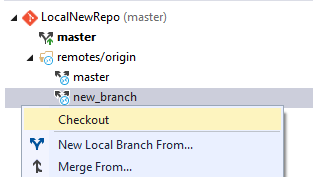
Il est possible d’effectuer l’action fetch sur une branche directement. Une fois la branche visible dans la remote voulue, un checkout permettra d’en créer une version locale sur laquelle il sera possible de travailler :
Command Line
Pour obtenir la liste des branches en ligne de commande, il est possible d’utiliser la commande branch et l’option -a :
git branch -a
Cette commande affichera donc une liste des branches des remotes du repository, ainsi que leur pendant local s’ils existent. La branche courante est aussi mise en valeur afin de la retrouver. Exemple de sortie de cette commande :
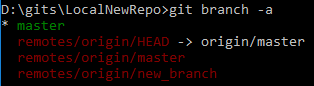
Si toutefois cette liste n’était pas à jour, une simple commande fetch permettrait de remédier à cela comme le montre la capture suivante :
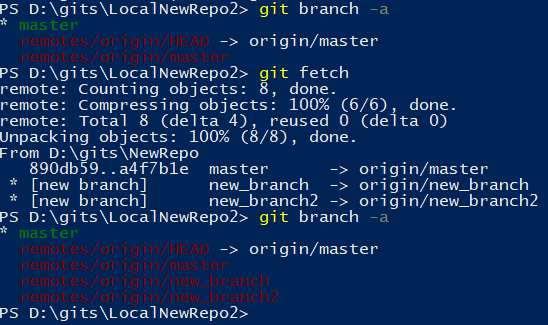
On y constate que les branches « new_branch » et « new_branch2 » sont listées après un fetch.
Pour travailler sur une de ces branches, il faut utiliser la commande checkout :
git checkout -b <branch> <remote>/<branch>
Par exemple :
git checkout -b new_branch origin/new_branch
Si la branche distante a déjà été récupérée, il est possible de changer de branche en ne se référant qu’à son nom (sans celui de la remote) :
git checkout <local_branch>
Attention, si vous effectuez un checkout en ne précisant que le nom de la branche distante (et la remote), il devient alors difficile de repartir sur un état stable. Voici un exemple plus concret :
git checkout <remote>/<branch>
Par exemple :
git checkout origin/new_branch
Le repository local se trouve alors dans un état dit « détaché ». C’est-à-dire que la copie de la branche distante a bien été faite, mais elle n’y est pas liée. Cela empêche les échanges de commits, ce qui est très gênant. Cet état a certainement une utilité que je ne saisis pas, mais je préconise d’en sortir au plus vite. Il faut donc créer une branche locale :
git checkout -b <branch>
Il est possible de nommer la branche locale comme on le souhaite, mais il est plus pertinent de lui donner le même nom que la branche distante pour éviter toute confusion. Il faut ensuite relier la branche locale à la branche distante :
git branch --set-upstream-to=<remote>/<branch> <branch>
Par exemple :
git branch --set-upstream-to=origin/new_branch new_branch
Il est ensuite possible de faire des commits et de les échanger avec le serveur via les commandes push et pull habituelles.
Merger une branche
Après avoir créé une branche, il est courant de vouloir faire figurer les modifications de celle-ci dans une autre. Une activité commune pour un développeur consiste par exemple à créer une branche à partir de la principale pour effectuer les modifications nécessaires à la réalisation d’une fonctionnalité. Une fois ces modifications testées et validées, il faut les intégrer à la branche principale pour en faire bénéficier le reste de l’équipe par exemple. Pour effectuer cela avec GIT, il faut toujours se placer sur la branche qui va être mise à jour lors du merge. Dans le cas présent, on se placerait donc sur la branche principale pour ensuite lancer une opération de merge de la branche dédiée à la nouvelle fonctionnalité.
Team Explorer
Pour réaliser cette opération dans Team Explorer, il faut se placer dans l’onglet des branches. Assurez-vous que la branche courante soit bien celle qui doit être mise à jour (effectuer un checkout si nécessaire). Un clic droit sur la branche à mettre jour permettra d’accéder à l’option « merge from ». Il sera ensuite possible de sélectionner la branche contenant les commits à rapatrier dans la branche courante comme le montre la capture suivante :
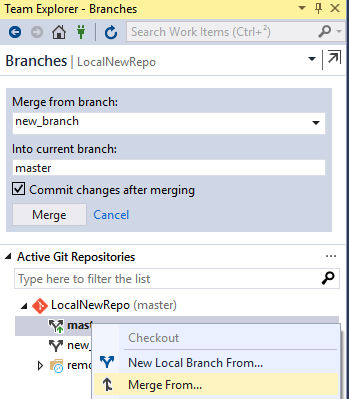
Command Line
En ligne de commande, il est aussi nécessaire de se placer sur la branche à mettre jour, ce qui peut être fait à l’aide de la commande checkout vu précédemment. La commande merge permettra ensuite de rapatrier une branche locale au sein de la branche courante :
git merge <branch>
Une opération de merge peut entrainer un conflit, qu’il faudra résoudre au même titre qu’une opération pull. En effet, du point de vue du repository, un merge est tout à fait comparable à une opération de pull : on vient incorporer depuis une autre souce une liste de commits. Après le merge, cette liste de commits est visible dans l’historique de la branche mise à jour. Le dernier commit représente quant à lui l’opération de merge qui a été effectuée et peut aussi contenir les modifications apportées lors de la résolution d’éventuels conflits.
Une opération de merge peut être une opération fastidieuse. Quel que soit le contrôle de code source employé, l’usage des branches requière de la rigueur et une bonne compréhension de l’équipe qui les emplois. Effectuer des merge régulièrement peut permettre d’en limiter la difficulté : plus une branche diverge d’une autre, plus il y a de risque que des conflits surviennent lors d’un merge. Toutefois, GIT simplifie les choses en ne permettant les merges que dans un sens et s’assure de par son fonctionnement interne qu’aucune donnée traquée ne puisse être perdue (dans la mesure où l’on ne fait pas appel aux options HARD qui vont altérer l’historique). Un merge peut donc facilement être annulé si nécessaire.
Supprimer une branche
Il arrive fréquemment dans le cycle de vie d’un projet qu’une branche ne soit plus utile. Il est donc légitime de chercher à la supprimer. Il n’est toutefois pas possible de supprimer la branche courante, il faut donc se placer sur une autre branche s’il s’agit du but à atteindre. Une branche existe aussi parfois à la fois en local, et sur le serveur. Si l’on souhaite supprimer en totalité la branche, il faut donc effectuer la suppression en local, mais aussi sur les remotes où elle se trouve. Il n’est normalement pas possible de supprimer une branche si celle-ci n’a pas été mergée dans la branche dont elle est issue (c’est-à-dire si des commits s’y trouvent et qu’ils ne sont pas dans la branche d’origine). Ce comportement peut toutefois être évité en faisant appel à certaines options.
Team Explorer
L’écran de liste des branches donne naturellement la possibilité d’en supprimer.
Commande Line
L’option --delete (abbrégé -d) de la commande branch permet de supprimer une branche locale :
git branch -d <branch>
Si une erreur apparait expliquant que la branche n’a pas été complètement mergée, il est possible d’en forcer la suppression avec l’option -D (les commits non mergés seront alors perdus) :
git branch -D <branch>
Combinée à l’option --remotes (ou -r), il semble possible de supprimer une branche d’une remote :
git branch -d -r <remote/branch>
Mais cette dernière commande ne produit pas tout à fait l’effet escompté. En effet, si l’on fait suivre d’une opération fetch, on verra réapparaitre la branche supprimée. Pour vraiment propager la suppression d’une branche distante, il faut utiliser la commande suivante push :
git push -d origin new_branch3
Toutefois, les autres machines ne seront pas forcément impactées par cette suppression. Il faudra donc y effectuer un fetch avec l’option --prune :
git fetch --all --prune
Trucs et astuces
L’utilisation des branches sous GIT est considéré comme l’un de ces plus gros atouts. Certaines situations sont tout de même parfois un peu difficile à résoudre. A suivre quelques cas particuliers et une technique possible pour arriver au but souhaité.
Impossible d’ignorer un fichier traqué
Lorsqu’un fichier est ajouté à un commit, celui-ci devient « traqué » par le repository. Ainsi les prochaines modifications effectuées sur celui-ci seront détectées. Il arrive parfois que l’on ajoute par mégarde des fichiers que l’on souhaiterait ignorer. On a donc naturellement tendance à l’ajouter au fichier gitignore. Toutefois, cette manipulation ne fonctionne pas, car le fichier est déjà traqué et le fichier gitignore permet d’exclure des fichiers non traqués seulement. Il faut donc commencer par supprimer le fichier en question :
git rm <file>
L’option -r permet de supprimer un répertoire récursivement, et l’option --cached permet d’ajouter la suppression au prochain commit sans pour autant supprimer physiquement le fichier du disque. Ceci fait, si le fichier gitignore est mis à jour, les manipulations apportées au fichier ne seront plus traquées comme voulu. Il faut évidemment créer un commit et en faire un push pour partager cette modification avec le reste de l’équipe. Toutefois, dans leur cas, le fichier sera supprimé même si l’option --cached avait été utilisée.
Créer une branche à partir des modifications en cours
Si les modifications apportées n’ont pas été commitées, il suffit de créer une branche en faisant un checkout dessus. Les modifications ne seront pas inclues sur la branche d’origine, puisque les commits suivants seront fait sur la nouvelle branche.
En revanche, si des commits locaux ont déjà été effectués sur la branche d’origine, mais que ceux-ci devraient figurer dans la nouvelle, quelques manipulations sont nécessaires. Il faut premièrement tirer une branche à partir de l’actuelle (on sauvegarde ainsi les modifications apportées dans une nouvelle branche et l’objectif est atteint pour celles-ci) :
git checkout -b <new_branch>
Il faut ensuite faire revenir la première branche dans son été d’origine. Il faut donc commencer par sauvegarder les commits dans la nouvelle branche :
git branch <new_branch>
Il faut ensuite faire disparaitre les commits de la branche actuelle avec la commande reset :
git reset --hard <id>
L’option --hard permet de faire disparaitre physiquement les modifications apportées. Elle peut être remplacée par l’option --soft qui créera un commit supplémentaire pour inverser les modifications. Dans cet exemple, le paramètre id doit être remplacé par un identifiant de commit marquant l’état dans lequel on souhaite remettre la branche. Des alias pratiques (comme HEAD^ permettant de cibler le commit précédent ou HEAD~ suivi d’un chiffre indiquant le nombre de commits précédents) simplifieront la manœuvre.
Nous avons vu dans cet article un usage sommaire des branches avec GIT et Team Explorer. Ce guide clos une série de trois articles concernant GIT et a pour but de présenter ce système de versioning, notamment pour des utilisateurs habitués de VSTS. Les cas d’usage décris en fin d’article ont régulièrement été rencontrés sur certains projets et les solutions apportées qui y sont décrites ont permis de résoudre les problèmes évoqués. Toutefois, il ne s’agit pas de solutions universelles, celles-ci dépendent de la situation et il est souvent possible d’arriver au même résultat avec d’autres manipulation. L’usage de l’option --hard doit être fait avec rigueur et en gardant à l’esprit qu’il peut en résulter une perte de donner si les précautions requises n’ont pas été prises.

Commentaires