
Tests d'intégrations ciblant SQLServer : améliorer les temps d'exécutions
Je suis un grand fan des tests automatisés et j'ai tendance à les imposer comme gage de qualité sur les projets où je passe. Les tests d'intégration font partie de la tranche la plus importante de la pyramide de tests et sont donc des plus nombreux. Plus le temps passe, plus ce nombre grandit et plus le temps d'exécution devient considérable et vite rédhibitoire pour les développeurs du projet : attendre plus de 15 minutes sur une PR, c'est long... Dans cet article, nous verrons quelques astuces afin d'optimiser le temps d'exécution de ces tests d'intégration.

Contexte
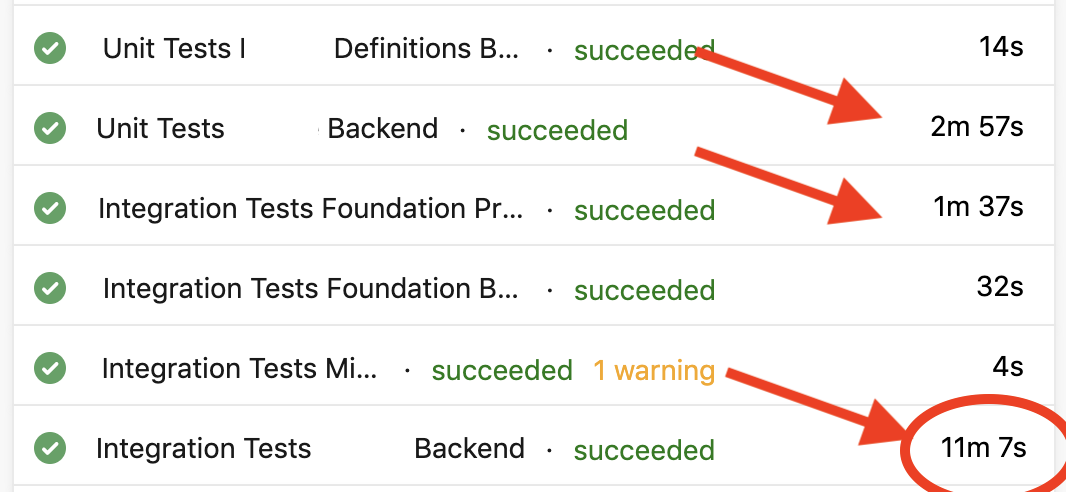
J'ai la chance de travailler sur un projet avec 2549 tests dont 322 tests d'intégration et 2227 tests unitaires. Ils sont joués à chaque PR et à chaque merge sur la branche de référence. On s'assure ainsi qu'aucun bug ou régression n'est introduit mais cela implique d'attendre que ces tests soient au vert avant de pouvoir obtenir un code considéré comme valide. C'est long.
Je suis convaincu qu'il faut absolument garder ce processus. C'est le prix à payer pour éviter des régressions à corriger a posteriori. Cependant, rien ne nous empêche de chercher à réduire ce temps au minimum. En analysant les différentes builds, j'ai pu assez rapidement trouver sur quelle partie axer mes tentatives d'amélioration des performances : les tests d'intégration.
Pour ma part, un test d'intégration consiste à vérifier que plusieurs systèmes interagissent bien entre eux une fois "branchés" ensemble. Je ne teste pas tous les cas fonctionnels (j'ai des tests unitaires pour cela), je vérifie simplement que le cas nominal fonctionne correctement. J'ai aussi quelques cas de tests pour vérifier les différents scénarios ne pouvant arriver que si tout est branché ensemble.
Anatomie d'un test
Dans le contexte de mon projet, les tests d'intégration consistent à brancher ensemble une API ASP.Net Core et un serveur SQL. Un grand classique donc ! Le déroulé de chacun des tests est le même :
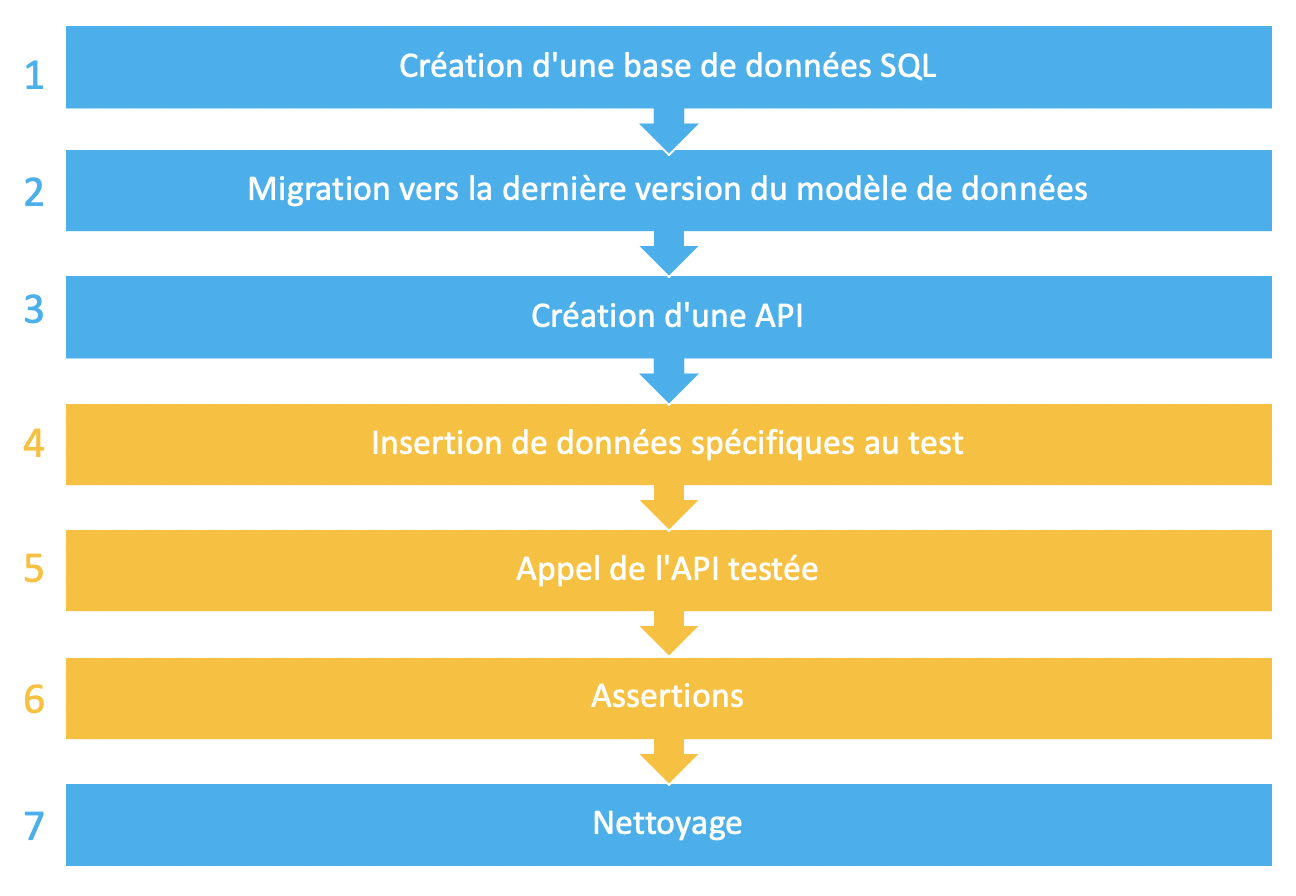
En bleu : ce qui est identique pour chaque test et en jaune ce qui est spécifique à chaque test.
Création d'une base SQL
J'utilise un seul et même serveur SQL sur lequel je crée une base de données spécifique à chacun de mes tests. Rien de compliqué pour cela : j'ai une chaîne de connexion à mon serveur SQL, je génère un nom de catalogue pour mon test et j'exécute un CREATE DATABASE dessus. Si le test échoue, vous pouvez ainsi retrouver facilement le contexte de données provocant l'erreur.
Je vous recommande de créer un serveur SQL sur une VM car les performances sont bien meilleures que sur du SQL Azure pour ce genre d'opérations.
Il s'agit d'une des étapes les plus chronophages du test : créer une base n'est pas anodin !
Migration vers la dernière version du modèle de données
Je migre cette base vers la dernière version du modèle de données. On utilise DbUp sous le capot pour migrer la base de données petit à petit, script par script. Dans notre cas, on part de zéro et on laisse DbUp exécuter chaque script un par un.
Un intérêt de cette démarche est que l'on teste en même temps, sur chaque test d'intégration, notre processus de migration du schéma de la base de données.
Là encore nous sommes confrontés à une étape chronophage du test car toucher au schéma d'une base prends du temps.
Création d'une API
Pour créer une instance de mon API, j'utilise la classe WebApplicationFactory du framework sans autre fioriture que la mise en place de la chaîne de connexion vers la base précédemment créée dans les paramètres en surchargeant la méthode CreateWebHostBuilder :
protected override IWebHostBuilder CreateWebHostBuilder () {
return new TProgram ().CreateWebHostBuilder (Array.Empty<string> ())
.ConfigureAppConfiguration (builder => {
builder.AddInMemoryCollection(
new Dictionary<string, string>
{
{ "ConnectionStrings:DefaultConnection", databaseConnectionString }
});
})
.UseStartup<TStartup> ();
}
Cette partie aussi est chronophage car elle implique la création d'une instance de notre API avec tout ce que cela implique : enregistrement des différents services (avec souvent de la réflexion impliquée dans le processus), enregistrement du DbContext (et sa configuration), etc. Ce n'est donc encore une fois pas une étape anodine en termes de temps d'exécution !
Insertion des données spécifiques au test
Cette étape est assez basique, on récupère un DbContext dans les services de l'API et on insère en base les données dont nous avons besoin pour tester l'API ciblée par le test.
On passe par la Factory créée précédemment afin d'obtenir un ServiceProvider nous donnant un DbContext :
// Obligatoire pour avoir un Server sur la factory
Factory.CreateClient().Dispose();
// création d'un scope
var scope = Factory.Server.Host.Services.CreateScope();
// récupération du DbContext
var dbContext =
scope.ServiceProvider.GetService<TDbContext>();
Cette étape est spécifique à votre test et en général elle ne prend pas trop de temps. Je vous recommande quand même de ne pas chercher à insérer des milliers de lignes en base...
Appel de l'API testée
On réalise alors le test réel de l'API en utilisant la Factory précédemment créée pour récupérer un HttpClient branché sur celle-ci. Sur notre projet, on utilise FlurlClient et cela donne ceci :
var httpClient = Factory.CreateClient();
var flurlClient = new FlurlClient(httpClient);
var response = await FlurlClient
.Request("/api/infiniteSquare/")
.AppendPathSegments("blog")
.GetJsonAsync<SwitchModel>();
Cette étape est en général peut coûteuse en termes de performances et permet de déclencher l'appel d'API dont vous voulez tester le comportement.
Assertions
Cette partie consiste à vérifier que l'API effectue bien ce qu'elle est doit faire. Pour cela on peut tester le retour de l'API ou encore le contenu de la base de données en utilisant le DbContext précédemment récupéré. Aussi, je vous recommande l'utilisation de FluentAssertions pour l'écriture des assertions.
Attention, si vous utilisez le DbContext, il faut certaines fois indiquer que l'entité que vous avez déjà précédemment obtenue de la base a été modifiée (car EF n'en a pas connaissance). Voici un exemple :
// test de la reponse HTTP
response.Should().NotBeNull();
response.IsSuccessStatusCode.Should().BeTrue(result);
// si on ne fait pas ça, EF ne sait pas que l'entité a été
// modifiée par ailleurs (par notre appel à l'API)
// et ne va pas la relire en base
DbContext.Entry(entityDejaRecupereeAvant).State = EntityState.Detached;
var recupéréeANouveau = DbContext.Blogs.
.FirstOrDefault(entity => entity.Id == entityDejaRecupereeAvant.Id);
recupéréeANouveau.Should().NotBeNull();
Nettoyage
La dernière étape consiste à nettoyer la base de données précédemment créée. Pour cela, on exécute une petite commande SQL magique :
var sql = "USE MASTER; SET DEADLOCK_PRIORITY HIGH;\r\n" +
$"WHILE EXISTS(SELECT NULL FROM sys.databases WHERE" +
" name='{catalogName}')\r\n" +
"BEGIN\r\n" +
$" DROP DATABASE [{catalogName}];\r\n" +
"END";
try
{
using (var conn = new SqlConnection(DatabaseConnectionString))
{
conn.Open();
var cmd = new SqlCommand(sql, conn) {
CommandType = CommandType.Text };
cmd.ExecuteNonQuery();
conn.Close();
}
}
catch (Exception)
{
}
Ce code est exécuté dans la méthode Dispose de notre test ou dans une class Fixture (pensez à lire cet article sur le sujet !).
À la recherche du temps perdu
En règle générale, il est difficile de gagner du temps sur les parties spécifiques à chaque test : sauf usage excessif, on crée peu d'entités et les assertions sont exécutées rapidement. On va donc essayer de travailler à optimiser les phases communes à chaque test :
- Création de la base de données,
- Migration de la base de données,
- Création de l'API,
- Nettoyage.
Snapshots SQL
Pour gagner du temps sur les étapes liées à la base de données, la première tentative fût d'utiliser les snapshots SQL Server.
Plutôt que de créer une base de données montée à la bonne version pour chaque test, nous faisons cela :
- [Premier test] Création de la base de données
- [Premier test] Migration vers la dernière version du schéma de données
- [Premier test] Création d'un snapshot
- Exécution du test
- [Test suivant ] Restauration du snapshot
- [Test suivant ] Exécution du test
- ..
- [Dernier test ] Exécution du test
- [Dernier test ] suppression du snapshot et de la base de données
Pour faciliter la mise en place de tout cela, on peut créer une fixture qui se charge de la logique :
public class SnapshotFixture : IDisposable {
private DatabaseSnapshot _snapshot;
public async Task InitAsync () {
if (_snapshot == null) {
// création de la base de données
...
// création du snapshot
_snapshot = new DatabaseSnapshot (
databaseCatalogName,
SnapshotPath,
databaseCatalogName + "_snapshot",
databaseConnectionString);
_snapshot.CreateSnapshot ();
} else {
_snapshot.RestoreSnapshot ();
}
}
public void Dispose () {
// suppression de la base
}
}
Cette fixture est alors utilisée par les classes de tests de la manière présentée ci-dessous. Pour éviter de le coder sur chaque classe de tests, pensez à mettre cela en place sur une classe de base :
public class MaClasseDeTests:
IClassFixture<SnapshotFixture>,
IAsyncLifetime {
private readonly SnapshotFixture _fixture;
public MaClasseDeTests (SnapshotFixture fixture) {
_fixture = fixture;
}
public Task InitializeAsync () {
return _fixture.InitAsync ();
}
public Task DisposeAsync () => Task.CompletedTask;
}
Une fois cette fixture et cette logique mises en place, on pourra déjà constater des gains de performances. Plus vos étapes de migration / création du schéma de données sont longues, plus cela sera visible.
Mais ce n'est pas assez : créer / restaurer un snapshot d'une base de données est en réalité assez long et peut faire perdre jusqu'à plusieurs secondes. Déception du public... il faut aller plus loin.
Respawn
En surfant sur l'internet mondial, j'ai pu découvrir un petit package Github bien sympathique : Respawn. Il nous promet de nettoyer intelligemment la base de données pour nos tests d'intégration.
Cette intelligence génère en réalité des appels Delete correctement ordonnancés sur les tables de votre base de données. La mise en oeuvre est ultra simple : on créé un Checkpoint au moment où toutes les tables existent et il suffit d'appeler la méthode Reset de celui-ci pour que le nettoyage s'opère (intelligemment). Il est aussi possible d'ignorer certaines tables pour garder en place des tables de référentiels par exemple.
Il est alors assez simple de modifier notre précédente fixture pour utiliser Respawn :
public class RespawnFixture : IDisposable {
private Checkpoint _checkpoint;
public async Task InitAsync () {
if (_snapshot == null) {
// création de la base de données
...
// création du checkpoint.
_checkpoint = new Checkpoint {
TablesToIgnore = new [] {
"AspNetUsers",
"AspNetUserRoles",
"AspNetRoles",
"AspNetUserTokens",
"AspNetUserLogins",
"AspNetUserClaims",
}
};
} else {
_checkpoint.Reset();
}
}
public void Dispose () {
// suppression de la base
}
}
Et nous ne sommes pas déçus ! Les tests s'exécutent bien plus rapidement : au lieu de prendre quelques secondes pour restaurer les snapshots, Respawn ne prends qu'entre 400 et 1200 ms (selon les manifestants et la police). Voici donc le moment où j'ajoute un GIF empreint de satisfaction.
De la bonne répartition des tests dans les collections
Il reste quand même un dernier élément à prendre en compte : la répartition des tests et l'utilisation de notre fixture.
Comme nous l'apprenons dans la documentation, par défaut Xunit :
- Place les tests d'une même classe dans une même collection.
- Joue parallèlement les tests de X différentes collections avec X étant le nombre de CPU de la machine.
- Joue séquentiellement les tests d'une même collection.
Avec ce que nous avons mis en place il y aura donc une base de données créées par classe de tests et X base de données utilisées en parallèle.
La première optimisation facile consiste à répartir vos tests sur des collections différentes :
- Une collection avec peu de tests va consommer beaucoup de temps à créer la base de données et la monter en version pour finalement la détruire après des temps de tests court... Une perte de temps peu eco-responsable. On corrige cela en créant des collections de tests regroupant les tests de plusieurs classes comme décrit dans ce précédent article.
- Une collection avec trop de tests va répartir le coût de création de la base de manière efficace sur tous les tests mais on va perdre beaucoup de temps à attendre que les tests soient joués l'un après l'autre. On pourra alors simplement créer deux classes pour répartir les tests sur celles-ci.
Cette simple action permet de gagner facilement beaucoup de temps d'exécution des tests mais nécessite d'être appliquée régulièrement sur votre projet au fur et à mesure que les tests sont rajoutés.
Database Pooling
Avec les explications précédentes en tête, on peut envisager un axe d'amélioration supplémentaire : le pooling de base de données bien sûr !! Plutôt que de créer une base au début de chaque exécution d'une collection de tests puis la supprimer à la fin, on va utiliser un pool de connexion. Si par exemple vous exécutez 16 collections de tests sur une machine à 4 cœurs, cela devrait vous permettre d'économiser 12 créations de base de données... ce n'est pas rien !
Chaque fixture demande une base de données de test au pool. S'il est vide, je créé une base de données, sinon j'en retourne une qui était disponible. Lors du nettoyage de la fixture, celle-ci replacera la base de données dans le pool.
Le code du pool est assez standard et prend en paramètre de son constructeur de quoi créer une instance des objets qu'il contient et une action permettant de nettoyer une instance précédemment créée.
public class TestContextPool<T> : IDisposable
{
private readonly ConcurrentBag<T> _objects;
private readonly Func<Task<T>> _objectGenerator;
private readonly Action<T> _objectCleaner;
public TestContextPool(
Func<Task<T>> objectGenerator,
Action<T> objectCleaner)
{
_objects = new ConcurrentBag<T>();
_objectGenerator = objectGenerator
?? throw new ArgumentNullException(nameof(objectGenerator));
_objectCleaner = objectCleaner;
}
public async Task<T> GetObjectAsync()
{
if (_objects.TryTake(out var item))
{
return item;
}
return await _objectGenerator().ConfigureAwait(false);
}
public void PutObject(T item)
{
_objects.Add(item);
}
public void Dispose()
{
foreach (var item in GetAllObject())
{
_objectCleaner(item);
}
}
private List<T> GetAllObject()
{
var instances = new List<T>();
while (_objects.TryTake(out var item))
{
instances.Add(item);
}
return instances;
}
}
Dans ce pool, je place des instances d'une classe que je nomme TestContext et qui contiendra alors les informations utiles à notre exécution de tests :
public class TestContext
{
public string DatabaseConnectionString { get; set; }
public Checkpoint Checkpoint { get; set; }
}
Je peux alors faire évoluer notre fixture pour utiliser un pool de données :
<br>public class SnapshotFixture : IDisposable {
private static TestContextPool<TestContext> _Pool
= new TestContextPool<TestContext> (
GenerateDatabaseAsync,
DeleteDatabase)
private static Task<TestContext> GenerateDatabaseAsync () {
// création du testContext avec le checkpoint dedans
}
private static void DeleteDatabase (TestContext testContext) {
...
}
private TestContext _testContext;
public async Task InitAsync () {
if (_testContext == null) {
_testContext = await _Pool.GetObjectAsync ();
} else {
_testContext.Checkpoint.Reset ();
}
}
public void Dispose () {
// on remets le test context dans le pool
TestContextPool.PutObject (_testContext);
}
}
Il reste cependant à nettoyer les bases de données créées lors l'exécution des tests puisqu'on ne le fait plus à la fin de chaque collection... Comment faire ? Tout simplement en utilisant l'assembly fixture présentée dans le précédent article de cette série de cette manière :
public class CleaningAssemblyFixture : IDisposable
{
public void Dispose()
{
MaFixture._Pool.Dispose();
}
}
Les effets de cette dernière optimisation sont aussi significatifs puisque l'on gagne beaucoup de temps sur la non-création de bases réutilisées du Pool.
API Pooling
Et si l'on faisait la même chose avec les Factory créées au début de chaque test ? Et bien oui, c'est une excellente idée très simple à mettre en place ! Il suffit d'ajouter notre factory sur notre objet TestContext et de lui faire utiliser la chaîne de connexion ciblant la base de ce TestContext : ils seront toujours utilisés ensemble et donc pas besoin de recréer une nouvelle API pour chaque test !
La méthode InitAsync de notre fixture devient donc :
public async Task InitAsync () {
if (_testContext == null) {
_testContext = await _Pool.GetObjectAsync ();
_testContext.Factory =
new MaFactory(_testContext.DatabaseConnectionString);
} else {
_testContext.Checkpoint.Reset ();
}
Et nous voici maintenant avec encore quelques précieuses dizaines de secondes économisées !
Conclusion
Et quels sont les temps d'exécution après tout cela ?
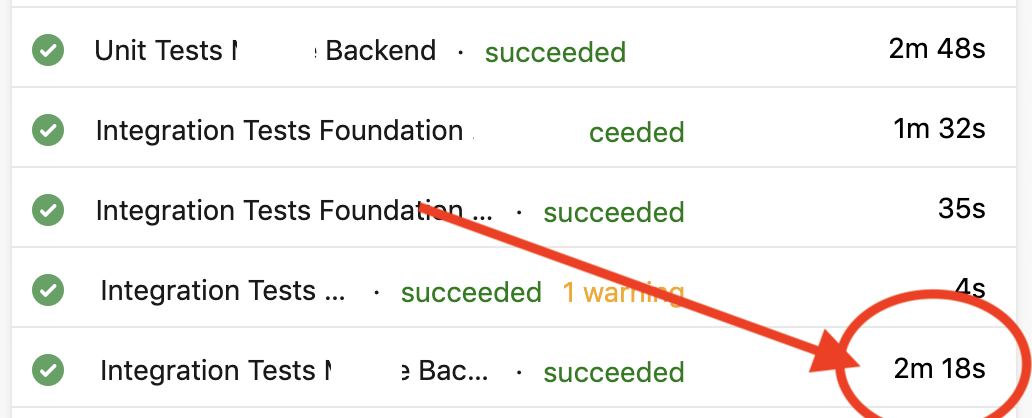
Yeah, on peut enfin sortir le GIF de victoire final !!
Qu'est ce que l'on a appris ?
Le code des tests est trop souvent pris à la légère : il a le mérite d'exister mais on ne prend pas toujours le temps d'y réfléchir pour le rendre performant. Hors, au bout d'un certain temps, cela nous revient à la figure avec des temps de build de plus en plus longs...

En écrivant cet article je me suis rendu compte qu'il fallait y réfléchir dès le départ pour avoir une base de code d'exécution des tests pensée pour la performance. Les tests sont eux aussi des citoyens de première classe de votre code source et il est important de les soigner, de les peaufiner au fur et à mesure. J'espère vous avoir vous aussi convaincus de cela...
Happy coding !


Commentaires